
Auto Scaling
Auto Scaling Simplified:
AWS Auto Scaling lets you build scaling plans that automate how groups of different resources respond to changes in demand. You can optimize availability, costs, or a balance of both. AWS Auto Scaling automatically creates all of the scaling policies and sets targets for you based on your preference.
Auto Scaling Key Details:
- Auto Scaling is a major benefit from the cloud’s economies of scale so if you ever have a requirement for scaling, automatically think of using the Auto Scaling service.
- Auto Scaling has three components:
- Groups: These are logical components. A webserver group of EC2 instances, a database group of RDS instances, etc.
- Configuration Templates: Groups use a template to configure and launch new instances to better match the scaling needs. You can specify information for the new instances like the AMI to use, the instance type, security groups, block devices to associate with the instances, and more.
- Scaling Options: Scaling Options provides several ways for you to scale your Auto Scaling groups. You can base the scaling trigger on the occurrence of a specified condition or on a schedule.
- The following image highlights the state of an Auto scaling group. The orange squares represent active instances. The dotted squares represent potential instances that can and will be spun up whenever necessary. The minimum number, the maximum number, and the desired capacity of instances are all entirely configurable.

- When you use Auto Scaling, your applications gain the following benefits:
- Better fault tolerance: Auto Scaling can detect when an instance is unhealthy, terminate it, and launch an instance to replace it. You can also configure Auto Scaling to use multiple Availability Zones. If one Availability Zone becomes unavailable, Auto Scaling can launch instances in another one to compensate.
- Better availability: Auto Scaling can help you ensure that your application always has the right amount of capacity to handle the current traffic demands.
- When it comes to actually scale your instance groups, the Auto Scaling service is flexible and can be done in various ways:
- Auto Scaling can scale based on the demand placed on your instances. This option automates the scaling process by specifying certain thresholds that, when reached, will trigger the scaling. This is the most popular implementation of Auto Scaling.
- Auto Scaling can ensure the current number of instances at all times. This option will always maintain the number of servers you want running even when they fail.
- Auto Scaling can scale only with manual intervention. If want to control all of the scaling yourself, this option makes sense.
- Auto Scaling can scale based on a schedule. If you can reliably predict spikes in traffic, this option makes sense.
- Auto Scaling based off of predictive scaling. This option lets AWS AI/ML learn more about your environment in order to predict the best time to scale for both performance improvements and cost-savings.
- In maintaining the current running instance, Auto Scaling will perform occasional health checks on the running instances to ensure that they are all healthy. When the service detects that an instance is unhealthy, it will terminate that instance and then bring up a new one online.
- When designing HA for your Auto Scaling, use multiple AZs and multiple regions wherever you can.
- Auto Scaling allows you to suspend and then resume one or more of the Auto Scaling processes in your Auto Scaling Group. This can be very useful when you want to investigate a problem in your application without triggering the Auto Scaling process when making changes.
- You can specify your launch configuration with multiple Auto Scaling groups. However, you can only specify one launch configuration for an Auto Scaling group at a time.
- You cannot modify a launch configuration after you’ve created it. If you want to change the launch configuration for an Auto Scaling group, you must create a new launch configuration and update your Auto Scaling group to inherit this new launch configuration.
Auto Scaling Default Termination Policy:
- The default termination policy for an Auto Scaling Group is to automatically terminate a stopped instance, so unless you’ve configured it to do otherwise, stopping an instance will result in termination regardless if you wanted that to happen or not. A new instance will be spun up in its place.
- The default termination policy will spare instances that you tell it in case some servers are running critical systems or applications. These critical servers are protected from “scale in”, which is just the deletion process of instances deemed superfluous to requirements.
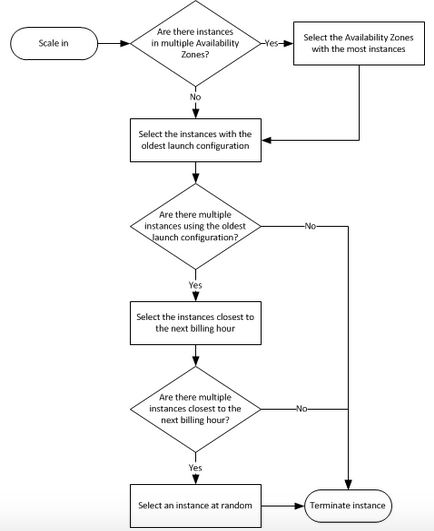
- The default termination policy is designed to help ensure that your network architecture spans Availability Zones evenly. With the default termination policy, the behavior of the Auto Scaling group is as follows:
- If there are instances in multiple Availability Zones, it will terminate an instance from the Availability Zone with the most instances. If there is more than one Availability Zone with the same max number of instances, it will choose the Availability Zone where instances use the oldest launch configuration.
- It will then determine which unprotected instances in the selected Availability Zone use the oldest launch configuration. If there is one such instance, it will terminate it.
- If there are multiple instances to terminate, it will determine which unprotected instances are closest to the next billing hour. (This helps you maximize the use of your EC2 instances and manage your Amazon EC2 usage costs.) If there are some instances that match this criteria, they will be terminated.
- This flow chart can provide further clarity on how the default Auto Scaling policy decides which instances to delete:
当前内容版权归 keenanromain 或其关联方所有,如需对内容或内容相关联开源项目进行关注与资助,请访问 keenanromain .


