
系统概览
Flume是百度INF和BDG团队联合开发的分布式数据流计算框架, 目标是提供比MapReduce更加灵活易用的计算模型. 众所周知,MapReduce 模型将数据处理分为 Map/Shuffle/Reduce 三个阶段, 降低了海量数据处理的开发难度, 对于普通的计算能够较好的支持. 但是在现实的数据处理中, 复杂的计算逻辑往往需要多轮 MapReduce, 这往往导致高昂的开发和运行成本.
Flume的设计参考了Google的FlumeJava和Apache的Spark, 将分布式计算看成是分布式数据集在算子上的变换. 这一抽象不显式指定分布式计算的轮数/方式, 而是更贴近描述用户的逻辑. Flume项目分成三个层次: Flume-Core,Flume-Api和Flume-Runtime. 如下图所示:
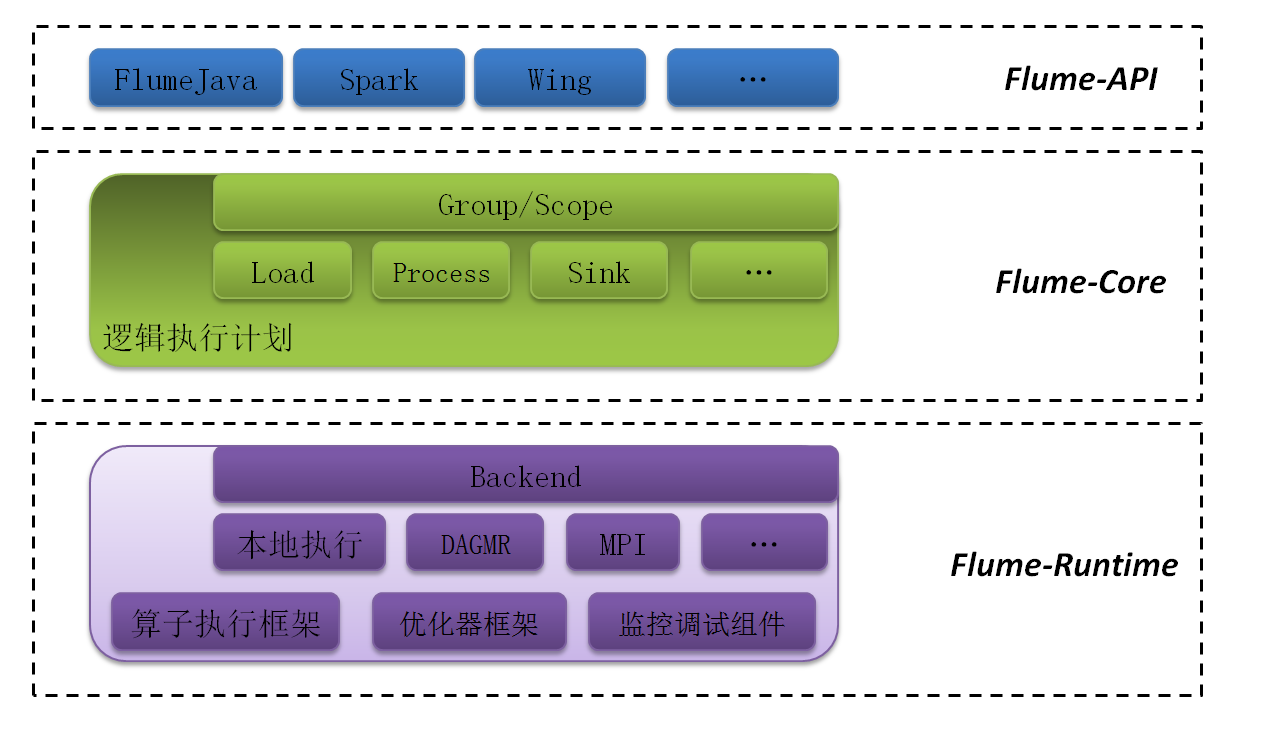
Flume-Api
Flume-Api层的目标是在Flume-Core的接口上提供面向终端用户的易用性接口, 它主要完成三方面的内容:
- 提供强类型的数据集抽象
- 提供易用的数据集操作接口
- 根据类型信息, 自动推导生成Flume-Core中的部分算子, 简化开发代价
Flume可以根据不同的需求和应用领域提供多套Api, 比如类似flumejava的Api和类似spark的Api, 都可以基于Flume-Core开发, 可以显著降低开发成本. 从这个角度看,INF的Bigflow和BDG的 Wing项目都是一种Flume-Api.
Flume-Core
Flume-Core是Flume的表示层, 提供了对分布式数据计算的抽象表示, 这一表示被称为 逻辑执行计划 , 该逻辑执行计划由分布式计算操作及其绑定算子组成. Flume-Core提供了一套接口来生成逻辑执行计划, 并可以在分布式环境下反射并执行用户的算子.
详见 Flume-Core
Flume-Runtime
Flume-Runtime是Flume的执行层, 其主要设计目标是提供一套通用的算子执行和优化机制, 可以使得用Flume-Core描述的逻辑执行计划能够在各种物理执行引擎上工作. 目前Flume-Runtime支持本地执行, 和在DAGMR上运行, 将来Flume还会扩展到更多的平台上(后注:现已支持Spark和公司内部的Gemini). 从这个角度看, Flume-Runtime本质上是一个通用的Worker运行时库.
详见


