
ReadWriteMany (RWX) Volume
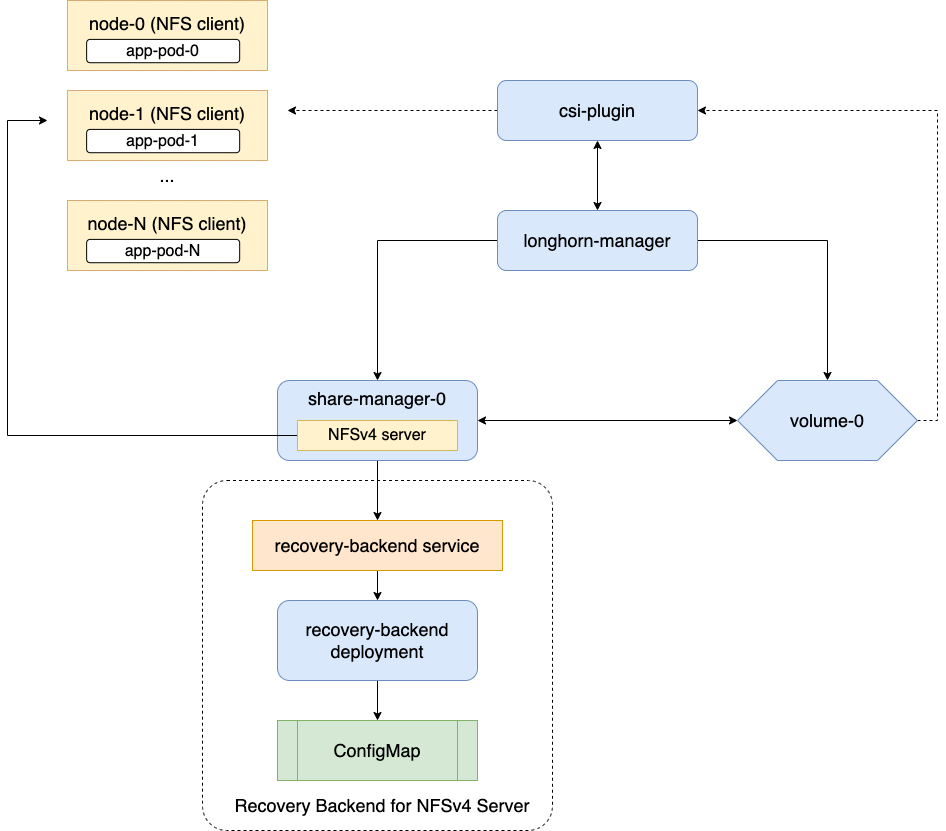
Longhorn supports ReadWriteMany (RWX) volumes by exposing regular Longhorn volumes via NFSv4 servers that reside in share-manager pods.
Introduction
Longhorn creates a dedicated share-manager-<volume-name> Pod within the longhorn-system namespace for each RWX volume that is currently in active use. The Pod facilitate the export of Longhorn volume via an internally hosted NFSv4 server. Additionally, a corresponding Service is created for each RWX volume, serving as the designated endpoint for actual NFSv4 client connections.
Requirements
It is necessary to meet the following requirements in order to use RWX volumes.
Each NFS client node needs to have a NFSv4 client installed.
Please refer to Installing NFSv4 client for more installation details.
Troubleshooting: If the NFSv4 client is not available on the node, when trying to mount the volume the below message will be part of the error:
for several filesystems (e.g. nfs, cifs) you might need a /sbin/mount.<type> helper program.
The hostname of each node is unique in the Kubernetes cluster.
There is a dedicated recovery backend service for NFS servers in Longhorn system. When a client connects to an NFS server, the client’s information, including its hostname, will be stored in the recovery backend. When a share-manager Pod or NFS server is abnormally terminated, Longhorn will create a new one. Within the 90-seconds grace period, clients will reclaim locks using the client information stored in the recovery backend.
Tip: The environment check script helps users to check all nodes have unique hostnames.
Notice
In versions 1.4.0 to 1.4.3 and 1.5.0 to 1.5.1 of Longhorn, Longhorn CSI plugin hard mounts a Longhorn volume exported by a NFS server located within a share-manager Pod in the NodeStageVolume. The hard mount allows NFS requests to persistently retry without termination, ensuring that IOs do not fail. When the server is back online or a replacement server is recreated, the IOs resume seamlessly, thus guaranteeing data integrity. However, to maintain file system stability, the Linux kernel will not permit unmounting a file system until all pending IOs are written back to storage, and the system cannot undergo shutdown until all file systems are unmounted. If the NFS server fails to recover successfully, the client nodes must undergo a forced reboot.
To address this stability problem, Longhorn switches to adopt the use of a softerr mount with a timeo value of 600 and a retrans value of 5 as default options since v1.4.4, 1.5.2 and 1.6.0. When the NFS server becomes unreachable due to factors such as node power outages, network partitions and so on, NFS clients will fail an NFS request after the specified number of retransmissions, resulting in an NFS ETIMEDOUT error being returned to the calling application and potential data loss. If softerr is not supported, Longhorn will automatically revert to using the soft option instead.
Please refer to #6655 for more information.
Creation and Usage of a RWX Volume
- For dynamically provisioned Longhorn volumes, the access mode is based on the PVC’s access mode.
- For manually created Longhorn volumes (restore, DR volume) the access mode can be specified during creation in the Longhorn UI.
- When creating a PV/PVC for a Longhorn volume via the UI, the access mode of the PV/PVC will be based on the volume’s access mode.
- One can change the Longhorn volume’s access mode via the UI as long as the volume is not bound to a PVC.
- For a Longhorn volume that gets used by a RWX PVC, the volume access mode will be changed to RWX.
Failure Handling
share-manager Pod is abnormally terminated
Client IO will be blocked until Longhorn creates a new share-manager Pod and the associated volume. Once the Pod is successfully created, the 90-seconds grace period for lock reclamation is started, and users would expect
- Before the grace period ends, client IO to the RWX volume will still be blocked.
- The server rejects READ and WRITE operations and non-reclaim locking requests with an error of NFS4ERR_GRACE.
- The grace period can be terminated early if all locks are successfully reclaimed.
After exiting the grace period, IOs of the clients successfully reclaiming the locks continue without stale file handle errors or IO errors. If a lock cannot be reclaimed within the grace period, the lock is discarded, and the server returns IO error to the client. The client re-establishes a new lock. The application should handle the IO error. Nevertheless, not all applications can handle IO errors due to their implementation. Thus, it may result in the failure of the IO operation and the data loss. Data consistency may be an issue.
Here is an example of a DaemonSet using a RWX volume.
Each Pod of the DaemonSet is writing data to the RWX volume. If the node, where the share-manager Pod is running, is down, a new share-manager Pod is created on another node. Since one of the clients located on the down node has gone, the lock reclaim process cannot be terminated earlier than 90-second grace period, even though the remaining clients’ locks have been successfully reclaimed. The IOs of these clients continue after the grace period has expired.
If the Kubernetes DNS service goes down, share-manager Pods will not be able to communicate with longhorn-nfs-recovery-backend
The NFS-ganesha server in a share-manager Pod communicates with longhorn-nfs-recovery-backend via the service
longhorn-recovery-backend‘s IP. If the DNS service is out of service, the creation and deletion of RWX volumes as well as the recovery of NFS servers will be inoperable. Thus, the high availability of the DNS service is recommended for avoiding the communication failure.
Migration from Previous External Provisioner
The below PVC creates a Kubernetes job that can copy data from one volume to another.
- Replace the
data-source-pvcwith the name of the previous NFSv4 RWX PVC that was created by Kubernetes. - Replace the
data-target-pvcwith the name of the new RWX PVC that you wish to use for your new workloads.
You can manually create a new RWX Longhorn volume + PVC/PV, or just create a RWX PVC and then have Longhorn dynamically provision a volume for you.
Both PVCs need to exist in the same namespace. If you were using a different namespace than the default, change the job’s namespace below.
apiVersion: batch/v1kind: Jobmetadata:namespace: default # namespace where the PVC's existname: volume-migrationspec:completions: 1parallelism: 1backoffLimit: 3template:metadata:name: volume-migrationlabels:name: volume-migrationspec:restartPolicy: Nevercontainers:- name: volume-migrationimage: ubuntu:xenialtty: truecommand: [ "/bin/sh" ]args: [ "-c", "cp -r -v /mnt/old /mnt/new" ]volumeMounts:- name: old-volmountPath: /mnt/old- name: new-volmountPath: /mnt/newvolumes:- name: old-volpersistentVolumeClaim:claimName: data-source-pvc # change to data source PVC- name: new-volpersistentVolumeClaim:claimName: data-target-pvc # change to data target PVC
History
- Available since v1.0.1 External provisioner
- Available since v1.1.0 Native RWX support
© 2019-2023 Longhorn Authors | Documentation Distributed under CC-BY-4.0
© 2023 The Linux Foundation. All rights reserved. The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our Trademark Usage page.



