
Quantization模型转换
提示
Quantized模型是对原模型进行转换过程中,将float参数转化为uint8类型,进而产生的模型会更小、运行更快,但是精度会有所下降。
前面我们介绍了Float 模型的转换方法,接下来我们要展示下 Quantized 模型,在TF1.0上,可以使用命令行工具转换 Quantized模型。在笔者尝试的情况看在TF2.0上,命令行工具目前只能转换为Float 模型,Python API只能转换为 Quantized 模型。
Python API转换方法如下:
- import tensorflow as tf
- converter = tf.lite.TFLiteConverter.from_saved_model('saved/1')
- converter.optimizations = [tf.lite.Optimize.DEFAULT]
- tflite_quant_model = converter.convert()
- open("mnist_savedmodel_quantized.tflite", "wb").write(tflite_quant_model)
最终转换后的 Quantized模型即为同级目录下的 mnist_savedmodel_quantized.tflite 。
相对TF1.0,上面的方法简化了很多,不需要考虑各种各样的参数,谷歌一直在优化开发者的使用体验。
在TF1.0上,我们可以使用 tflite_convert 获得模型具体结构,然后通过graphviz转换为pdf或png等方便查看。在TF2.0上,提供了新的一步到位的工具 visualize.py ,直接转换为html文件,除了模型结构,还有更清晰的关键信息总结。
提示
visualize.py 目前看应该还是开发阶段,使用前需要先从github下载最新的 TensorFlow 和 FlatBuffers 源码,并且两者要在同一目录,因为 visualize.py 源码中是按两者在同一目录写的调用路径。
下载 TensorFlow:
- git clone [email protected]:tensorflow/tensorflow.git
下载 FlatBuffers:
- git clone [email protected]:google/flatbuffers.git
编译 FlatBuffers:(笔者使用的Mac,其他平台请大家自行配置,应该不麻烦)
下载cmake:执行
brew install cmake设置编译环境:在
FlatBuffers的根目录,执行cmake -G "Unix Makefiles" -DCMAKE_BUILD_TYPE=Release编译:在
FlatBuffers的根目录,执行make
编译完成后,会在跟目录生成 flatc,这个可执行文件是 visualize.py 运行所依赖的。
visualize.py使用方法
在tensorflow/tensorflow/lite/tools目录下,执行如下命令
- python visualize.py mnist_savedmodel_quantized.tflite mnist_savedmodel_quantized.html
生成可视化报告的关键信息
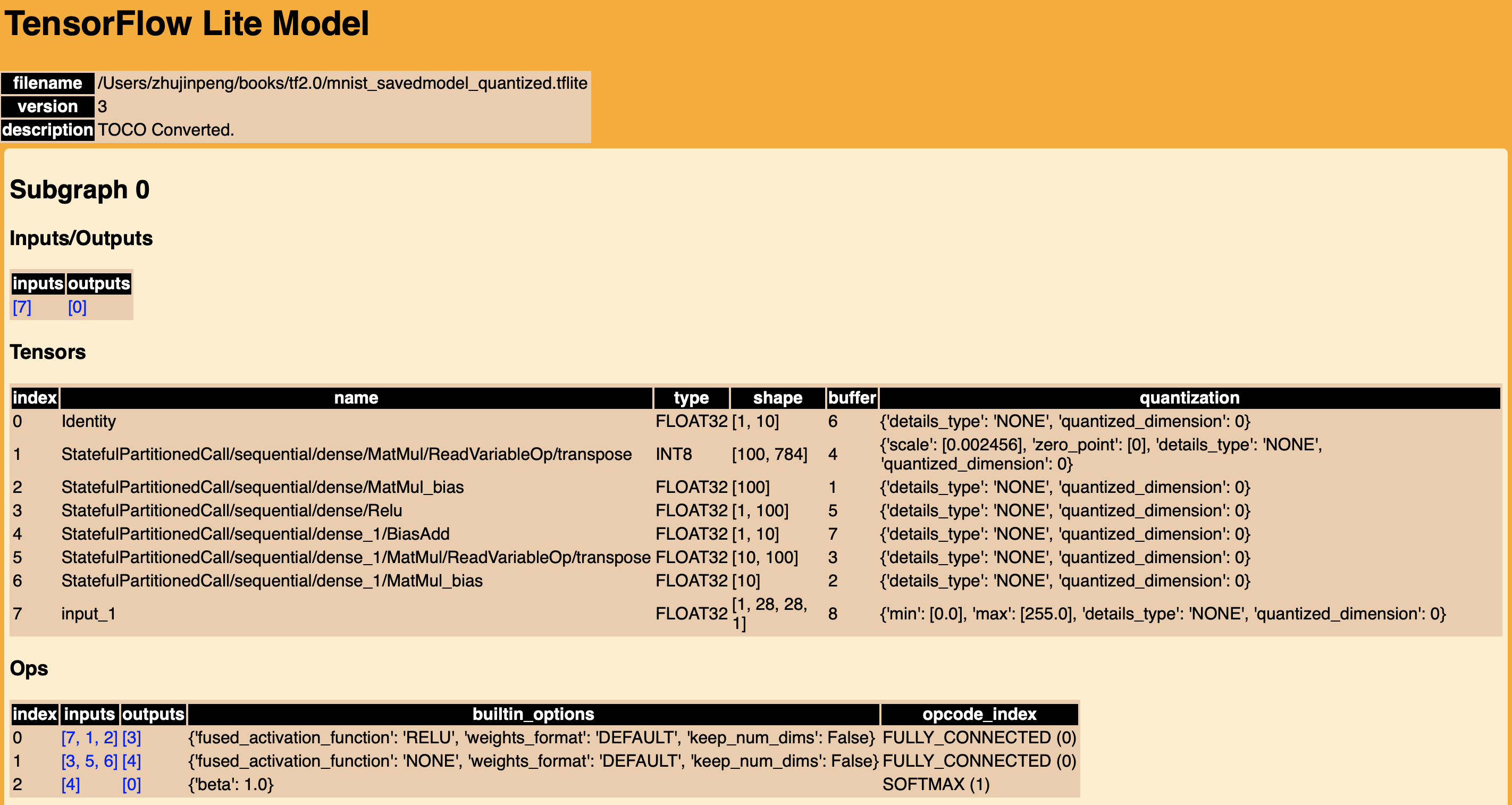
模型结构
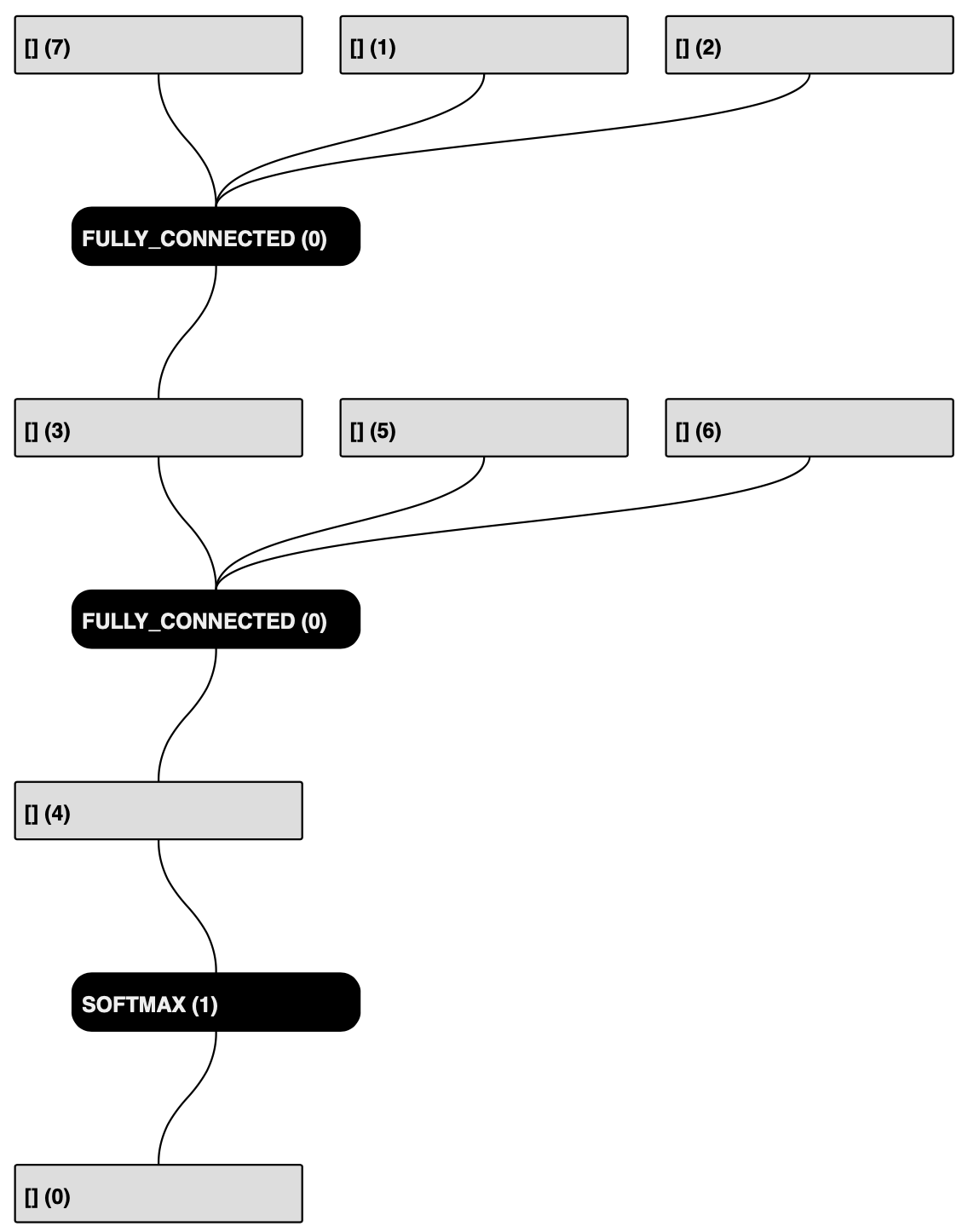
可见,Input/Output格式都是 FLOAT32 的多维数组,Input的min和max分别是0.0和255.0。
跟Float模型对比,Input/Output格式是一致的,所以可以复用Float模型Android部署过程中的配置。
提示
暂不确定这里是否是TF2.0上的优化,如果是这样的话,对开发者来说是非常友好的,如此就归一化了Float和Quantized模型处理了。
具体配置如下:
- // Quantized模型相关参数
- // com/dpthinker/mnistclassifier/model/QuantSavedModelConfig.java
- public class QuantSavedModelConfig extends BaseModelConfig {
- @Override
- protected void setConfigs() {
- setModelName("mnist_savedmodel_quantized.tflite");
- setNumBytesPerChannel(4);
- setDimBatchSize(1);
- setDimPixelSize(1);
- setDimImgWeight(28);
- setDimImgHeight(28);
- setImageMean(0);
- setImageSTD(255.0f);
- }
- @Override
- public void addImgValue(ByteBuffer imgData, int val) {
- imgData.putFloat(((val & 0xFF) - getImageMean()) / getImageSTD());
- }
- }
运行效果如下:
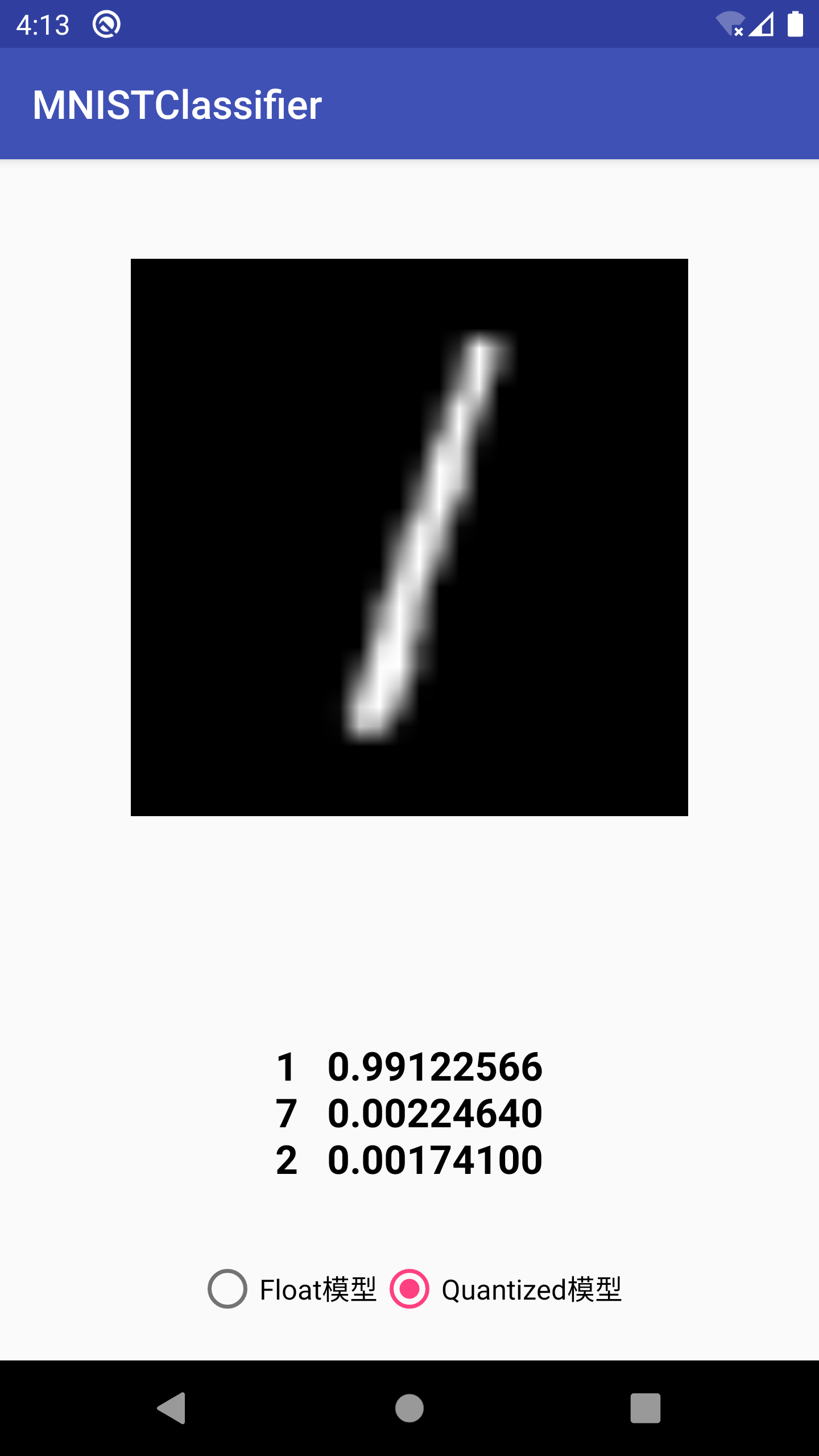
Float模型与 Quantized模型大小与性能对比:
可见, Quantized模型在模型大小和运行性能上相对Float模型都有非常大的提升。不过,在笔者试验的过程中,发现有些图片在Float模型上识别正确的,在 Quantized模型上会识别错,可见 Quantization 对模型的识别精度还是有影响的。在边缘设备上资源有限,需要在模型大小、运行速度与识别精度上找到一个权衡。


