
关于数据系统的思考
我们通常认为,数据库、消息队列、缓存等工具分属于几个差异显著的类别。虽然数据库和消息队列表面上有一些相似性——它们都会存储一段时间的数据——但它们有迥然不同的访问模式,这意味着迥异的性能特征和实现手段。
那我们为什么要把这些东西放在 数据系统(data system) 的总称之下混为一谈呢?
近些年来,出现了许多新的数据存储工具与数据处理工具。它们针对不同应用场景进行优化,因此不再适合生硬地归入传统类别【1】。类别之间的界限变得越来越模糊,例如:数据存储可以被当成消息队列用(Redis),消息队列则带有类似数据库的持久保证(Apache Kafka)。
其次,越来越多的应用程序有着各种严格而广泛的要求,单个工具不足以满足所有的数据处理和存储需求。取而代之的是,总体工作被拆分成一系列能被单个工具高效完成的任务,并通过应用代码将它们缝合起来。
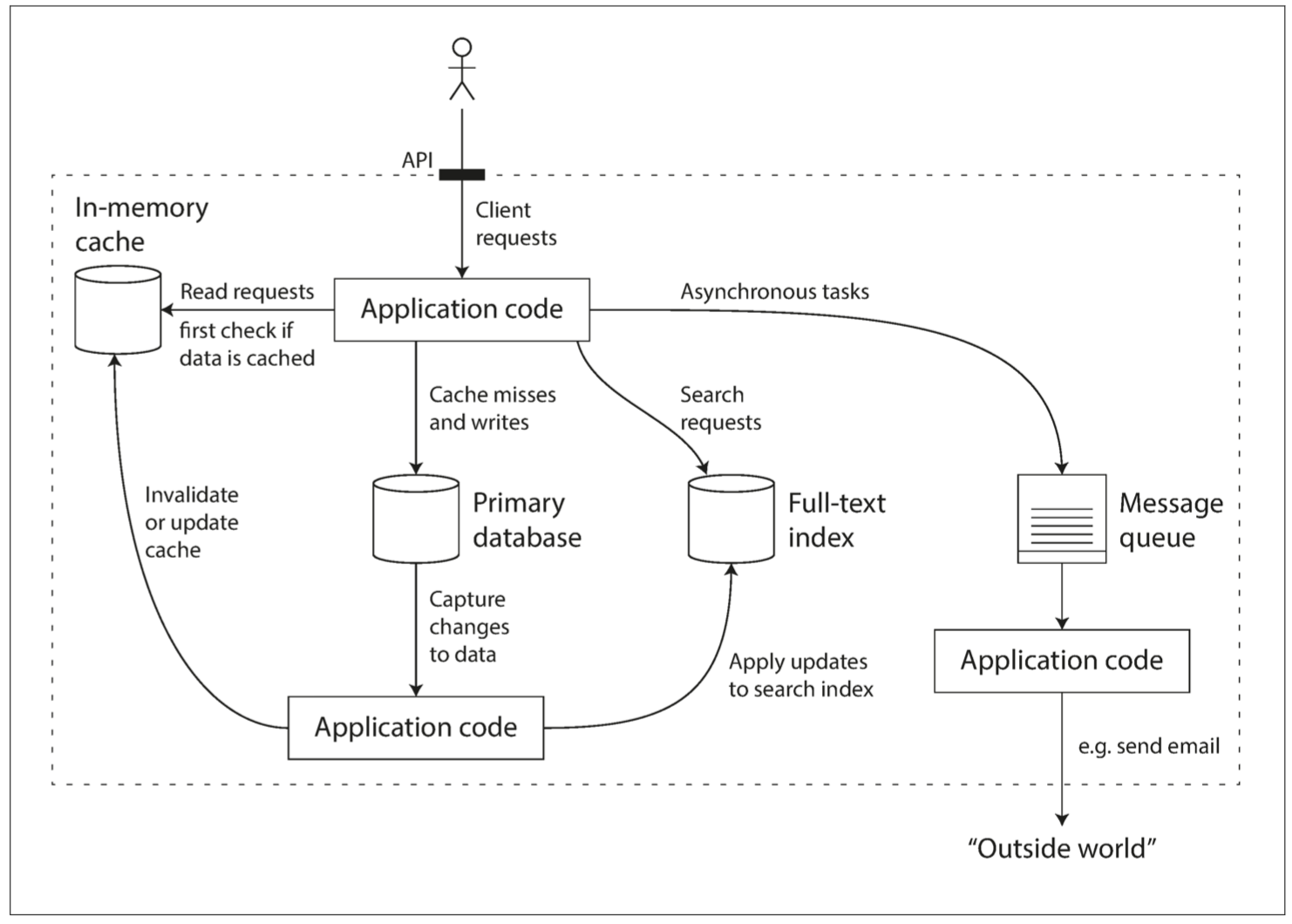
例如,如果将缓存(应用管理的缓存层,Memcached或同类产品)和全文搜索(全文搜索服务器,例如Elasticsearch或Solr)功能从主数据库剥离出来,那么使缓存/索引与主数据库保持同步通常是应用代码的责任。图1-1 给出了这种架构可能的样子(细节将在后面的章节中详细介绍)。

图1-1 一个可能的组合使用多个组件的数据系统架构
当你将多个工具组合在一起提供服务时,服务的接口或应用程序编程接口(API, Application Programming Interface)通常向客户端隐藏这些实现细节。现在,你基本上已经使用较小的通用组件创建了一个全新的、专用的数据系统。这个新的复合数据系统可能会提供特定的保证,例如:缓存在写入时会作废或更新,以便外部客户端获取一致的结果。现在你不仅是应用程序开发人员,还是数据系统设计人员了。
设计数据系统或服务时可能会遇到很多棘手的问题,例如:当系统出问题时,如何确保数据的正确性和完整性?当部分系统退化降级时,如何为客户提供始终如一的良好性能?当负载增加时,如何扩容应对?什么样的API才是好的API?
影响数据系统设计的因素很多,包括参与人员的技能和经验、历史遗留问题、系统路径依赖、交付时限、公司的风险容忍度、监管约束等,这些因素都需要具体问题具体分析。
本书着重讨论三个在大多数软件系统中都很重要的问题:
可靠性(Reliability)
系统在困境(adversity)(硬件故障、软件故障、人为错误)中仍可正常工作(正确完成功能,并能达到期望的性能水准)。
可扩展性(Scalability)
有合理的办法应对系统的增长(数据量、流量、复杂性)(参阅“可扩展性”)
可维护性(Maintainability)
许多不同的人(工程师、运维)在不同的生命周期,都能高效地在系统上工作(使系统保持现有行为,并适应新的应用场景)。(参阅”可维护性“)
人们经常追求这些词汇,却没有清楚理解它们到底意味着什么。为了工程的严谨性,本章的剩余部分将探讨可靠性、可扩展性、可维护性的含义。为实现这些目标而使用的各种技术,架构和算法将在后续的章节中研究。



{kind=link}