
列存储
如果事实表中有万亿行和数PB的数据,那么高效地存储和查询它们就成为一个具有挑战性的问题。维度表通常要小得多(数百万行),所以在本节中我们将主要关注事实的存储。
尽管事实表通常超过100列,但典型的数据仓库查询一次只能访问4个或5个查询( “ SELECT * ” 查询很少用于分析)【51】。以例3-1中的查询为例:它访问了大量的行(在2013日历年中每次都有人购买水果或糖果),但只需访问fact_sales表的三列:date_key, product_sk, quantity。查询忽略所有其他列。
例3-1 分析人们是否更倾向于购买新鲜水果或糖果,这取决于一周中的哪一天
SELECTdim_date.weekday,dim_product.category,SUM(fact_sales.quantity) AS quantity_soldFROM fact_salesJOIN dim_date ON fact_sales.date_key = dim_date.date_keyJOIN dim_product ON fact_sales.product_sk = dim_product.product_skWHEREdim_date.year = 2013 ANDdim_product.category IN ('Fresh fruit', 'Candy')GROUP BYdim_date.weekday, dim_product.category;
我们如何有效地执行这个查询?
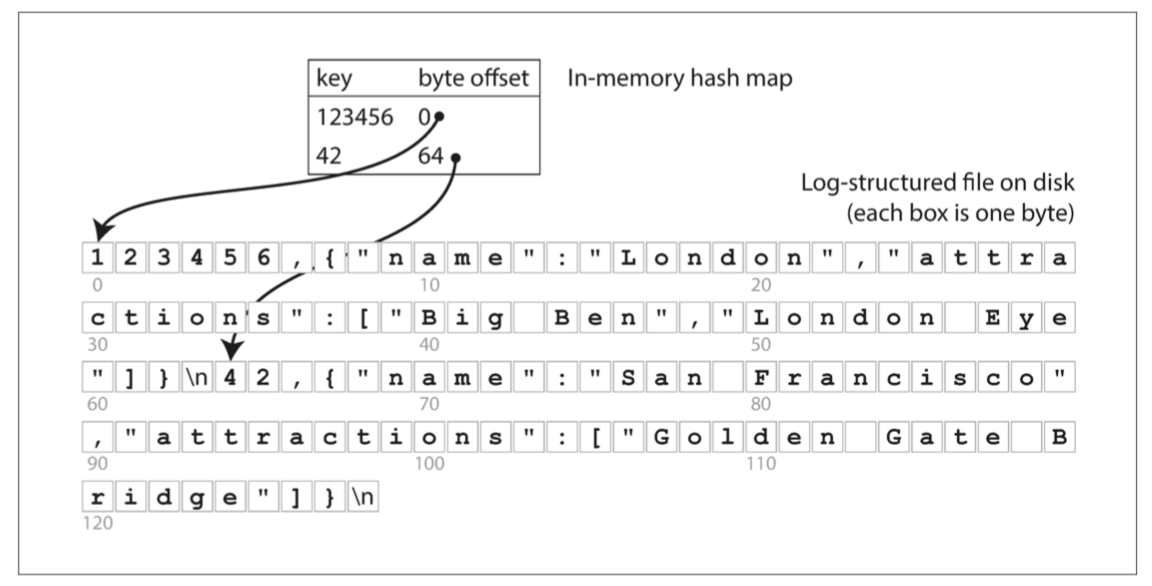
在大多数OLTP数据库中,存储都是以面向行的方式进行布局的:表格的一行中的所有值都相邻存储。文档数据库是相似的:整个文档通常存储为一个连续的字节序列。你可以在图3-1的CSV例子中看到这个。
为了处理像例3-1这样的查询,您可能在 fact_sales.date_key, fact_sales.product_sk上有索引,它们告诉存储引擎在哪里查找特定日期或特定产品的所有销售情况。但是,面向行的存储引擎仍然需要将所有这些行(每个包含超过100个属性)从磁盘加载到内存中,解析它们,并过滤掉那些不符合要求的条件。这可能需要很长时间。
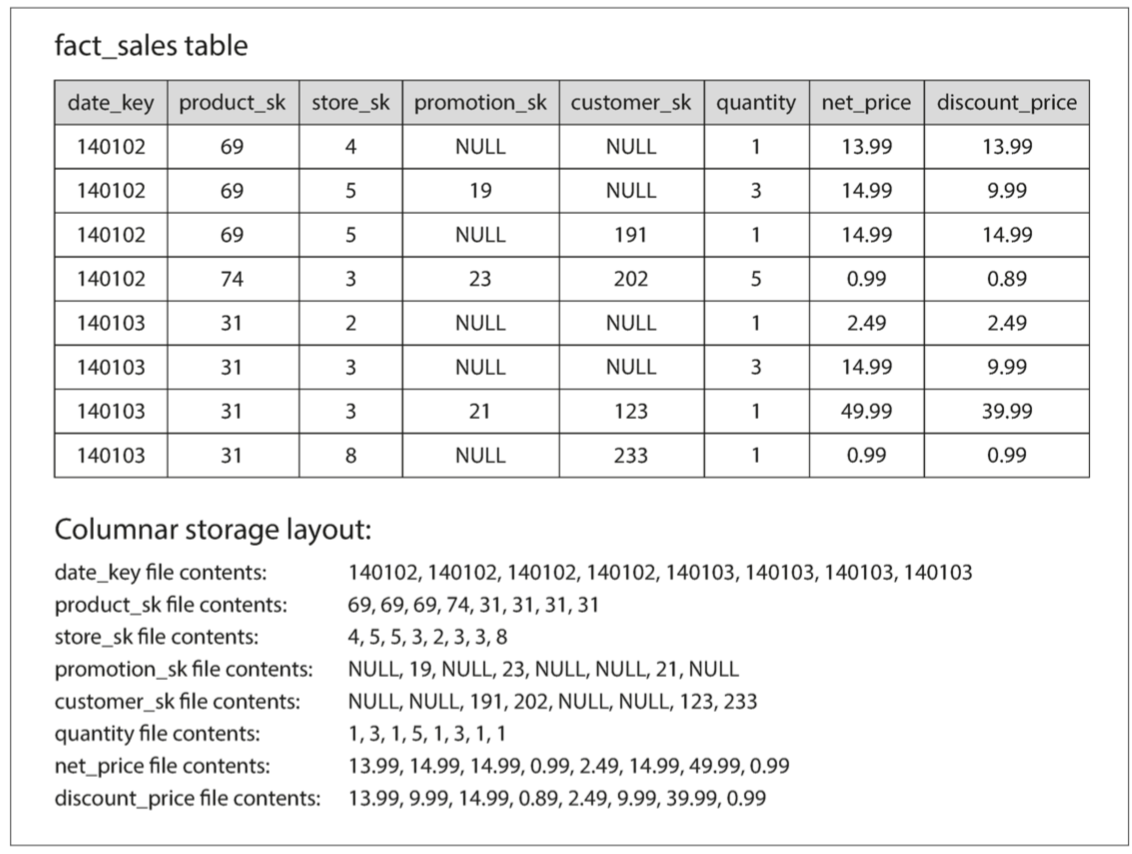
面向列的存储背后的想法很简单:不要将所有来自一行的值存储在一起,而是将来自每一列的所有值存储在一起。如果每个列存储在一个单独的文件中,查询只需要读取和解析查询中使用的那些列,这可以节省大量的工作。这个原理如图3-10所示。

图3-10 使用列存储关系型数据,而不是行
列存储在关系数据模型中是最容易理解的,但它同样适用于非关系数据。例如,Parquet 【57】是一种列式存储格式,支持基于Google的Dremel 【54】的文档数据模型。
面向列的存储布局依赖于包含相同顺序行的每个列文件。 因此,如果您需要重新组装整行,您可以从每个单独的列文件中获取第23项,并将它们放在一起形成表的第23行。
列压缩
除了仅从磁盘加载查询所需的列以外,我们还可以通过压缩数据来进一步降低对磁盘吞吐量的需求。幸运的是,面向列的存储通常很适合压缩。
看看图3-10中每一列的值序列:它们通常看起来是相当重复的,这是压缩的好兆头。根据列中的数据,可以使用不同的压缩技术。在数据仓库中特别有效的一种技术是位图编码,如图3-11所示。
图3-11 压缩位图索引存储布局
通常情况下,一列中不同值的数量与行数相比较小(例如,零售商可能有数十亿的销售交易,但只有100,000个不同的产品)。现在我们可以得到一个有 n 个不同值的列,并把它转换成 n 个独立的位图:每个不同值的一个位图,每行一位。如果该行具有该值,则该位为 1 ,否则为 0 。
如果 n 非常小(例如,国家/地区列可能有大约200个不同的值),则这些位图可以每行存储一位。但是,如果n更大,大部分位图中将会有很多的零(我们说它们是稀疏的)。在这种情况下,位图可以另外进行游程编码,如图3-11底部所示。这可以使列的编码非常紧凑。
这些位图索引非常适合数据仓库中常见的各种查询。例如:
WHERE product_sk IN(30,68,69)
加载 product_sk = 30 , product_sk = 68 , product_sk = 69 的三个位图,并计算三个位图的按位或,这可以非常有效地完成。
WHERE product_sk = 31 AND store_sk = 3
加载 product_sk = 31 和 store_sk = 3 的位图,并逐位计算AND。 这是因为列按照相同的顺序包含行,因此一列的位图中的第 k 位对应于与另一列的位图中的第 k 位相同的行。
对于不同种类的数据,也有各种不同的压缩方案,但我们不会详细讨论它们,参见【58】的概述。
面向列的存储和列族
Cassandra和HBase有一个列族的概念,他们从Bigtable继承【9】。然而,把它们称为面向列是非常具有误导性的:在每个列族中,它们将一行中的所有列与行键一起存储,并且不使用列压缩。因此,Bigtable模型仍然主要是面向行的。
内存带宽和向量处理
对于需要扫描数百万行的数据仓库查询来说,一个巨大的瓶颈是从磁盘获取数据到内存的带宽。但是,这不是唯一的瓶颈。分析数据库的开发人员也担心有效利用主存储器带宽到CPU缓存中的带宽,避免CPU指令处理流水线中的分支错误预测和泡沫,以及在现代中使用单指令多数据(SIMD)指令CPU 【59,60】。
除了减少需要从磁盘加载的数据量以外,面向列的存储布局也可以有效利用CPU周期。例如,查询引擎可以将大量压缩的列数据放在CPU的L1缓存中,然后在紧密的循环中循环(即没有函数调用)。一个CPU可以执行这样一个循环比代码要快得多,这个代码需要处理每个记录的大量函数调用和条件。列压缩允许列中的更多行适合相同数量的L1缓存。前面描述的按位“与”和“或”运算符可以被设计为直接在这样的压缩列数据块上操作。这种技术被称为矢量化处理【58,49】。
列存储中的排序顺序
在列存储中,存储行的顺序并不一定很重要。按插入顺序存储它们是最简单的,因为插入一个新行就意味着附加到每个列文件。但是,我们可以选择强制执行一个命令,就像我们之前对SSTables所做的那样,并将其用作索引机制。
注意,每列独自排序是没有意义的,因为那样我们就不会知道列中的哪些项属于同一行。我们只能重建一行,因为我们知道一列中的第k项与另一列中的第k项属于同一行。
相反,即使按列存储数据,也需要一次对整行进行排序。数据库的管理员可以使用他们对常见查询的知识来选择表格应该被排序的列。例如,如果查询通常以日期范围为目标,例如上个月,则可以将 date_key 作为第一个排序键。然后,查询优化器只能扫描上个月的行,这比扫描所有行要快得多。
第二列可以确定第一列中具有相同值的任何行的排序顺序。例如,如果 date_key 是图3-10中的第一个排序关键字,那么 product_sk 可能是第二个排序关键字,因此同一天的同一产品的所有销售都将在存储中组合在一起。这将有助于需要在特定日期范围内按产品对销售进行分组或过滤的查询。
排序顺序的另一个好处是它可以帮助压缩列。如果主要排序列没有多个不同的值,那么在排序之后,它将具有很长的序列,其中相同的值连续重复多次。一个简单的运行长度编码(就像我们用于图3-11中的位图一样)可以将该列压缩到几千字节 —— 即使表中有数十亿行。
第一个排序键的压缩效果最强。第二和第三个排序键会更混乱,因此不会有这么长时间的重复值。排序优先级下面的列以基本上随机的顺序出现,所以它们可能不会被压缩。但前几列排序仍然是一个整体。
几个不同的排序顺序
这个想法的巧妙扩展在C-Store中引入,并在商业数据仓库Vertica【61,62】中被采用。不同的查询受益于不同的排序顺序,为什么不以相同的方式存储相同的数据呢?无论如何,数据需要复制到多台机器,这样,如果一台机器发生故障,您不会丢失数据。您可能还需要存储以不同方式排序的冗余数据,以便在处理查询时,可以使用最适合查询模式的版本。
在一个面向列的存储中有多个排序顺序有点类似于在一个面向行的存储中有多个二级索引。但最大的区别在于面向行的存储将每一行保存在一个地方(在堆文件或聚簇索引中),二级索引只包含指向匹配行的指针。在列存储中,通常在其他地方没有任何指向数据的指针,只有包含值的列。
写入列存储
这些优化在数据仓库中是有意义的,因为大多数负载由分析人员运行的大型只读查询组成。面向列的存储,压缩和排序都有助于更快地读取这些查询。然而,他们有写更加困难的缺点。
使用B树的更新就地方法对于压缩的列是不可能的。如果你想在排序表的中间插入一行,你很可能不得不重写所有的列文件。由于行由列中的位置标识,因此插入必须始终更新所有列。
幸运的是,本章前面已经看到了一个很好的解决方案:LSM树。所有的写操作首先进入一个内存中的存储,在这里它们被添加到一个已排序的结构中,并准备写入磁盘。内存中的存储是面向行还是列的,这并不重要。当已经积累了足够的写入数据时,它们将与磁盘上的列文件合并,并批量写入新文件。这基本上是Vertica所做的【62】。
查询需要检查磁盘上的列数据和最近在内存中的写入,并将两者结合起来。但是,查询优化器隐藏了用户的这个区别。从分析师的角度来看,通过插入,更新或删除操作进行修改的数据会立即反映在后续查询中。
聚合:数据立方体和物化视图
并不是每个数据仓库都必定是一个列存储:传统的面向行的数据库和其他一些架构也被使用。然而,对于专门的分析查询,列式存储可以显著加快,所以它正在迅速普及【51,63】。
数据仓库的另一个值得一提的是物化汇总。如前所述,数据仓库查询通常涉及一个聚合函数,如SQL中的COUNT,SUM,AVG,MIN或MAX。如果相同的聚合被许多不同的查询使用,那么每次都可以通过原始数据来处理。为什么不缓存一些查询使用最频繁的计数或总和?
创建这种缓存的一种方式是物化视图。在关系数据模型中,它通常被定义为一个标准(虚拟)视图:一个类似于表的对象,其内容是一些查询的结果。不同的是,物化视图是查询结果的实际副本,写入磁盘,而虚拟视图只是写入查询的捷径。从虚拟视图读取时,SQL引擎会将其展开到视图的底层查询中,然后处理展开的查询。
当底层数据发生变化时,物化视图需要更新,因为它是数据的非规范化副本。数据库可以自动完成,但是这样的更新使得写入成本更高,这就是在OLTP数据库中不经常使用物化视图的原因。在读取繁重的数据仓库中,它们可能更有意义(不管它们是否实际上改善了读取性能取决于个别情况)。
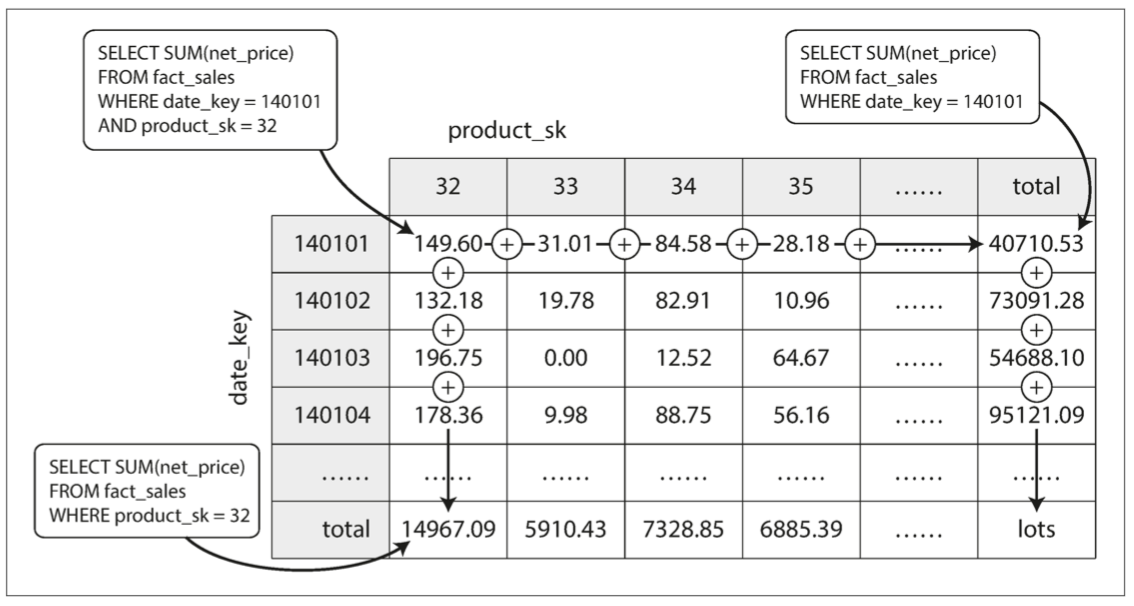
物化视图的常见特例称为数据立方体或OLAP立方【64】。它是按不同维度分组的聚合网格。图3-12显示了一个例子。
图3-12 数据立方的两个维度,通过求和聚合
想象一下,现在每个事实都只有两个维度表的外键——在图3-12中,这些是日期和产品。您现在可以绘制一个二维表格,一个轴线上的日期和另一个轴上的产品。每个单元包含具有该日期 - 产品组合的所有事实的属性(例如,net_price)的聚集(例如,SUM)。然后,您可以沿着每行或每列应用相同的汇总,并获得一个维度减少的汇总(按产品的销售额,无论日期,还是按日期销售,无论产品如何)。
一般来说,事实往往有两个以上的维度。在图3-9中有五个维度:日期,产品,商店,促销和客户。要想象一个五维超立方体是什么样子是很困难的,但是原理是一样的:每个单元格都包含特定日期(产品-商店-促销-客户)组合的销售。这些值可以在每个维度上重复概括。
物化数据立方体的优点是某些查询变得非常快,因为它们已经被有效地预先计算了。例如,如果您想知道每个商店的总销售额,则只需查看合适维度的总计,无需扫描数百万行。
缺点是数据立方体不具有查询原始数据的灵活性。例如,没有办法计算哪个销售比例来自成本超过100美元的项目,因为价格不是其中的一个维度。因此,大多数数据仓库试图保留尽可能多的原始数据,并将聚合数据(如数据立方体)仅用作某些查询的性能提升。



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}