
C/C++ 开发环境(终端)
Linux 终端系统,例如 Ubuntu 服务器版 ,是不带图形桌面的。因此,在终端系统上做开发,只能依赖一些命令行工具,与 IDE 环境颇有不同。
C 语言
在 Linux 下,一般使用 gcc 编译 C 语言代码。gcc 可以通过包管理工具进行安装,以 Ubuntu 为例:
$ sudo apt install gcc
接下来,我们编译一个非常简单的 C 语言程序 hello_world.c 。代码如下:
#include <stdio.h>int main() {printf("Hello, world!\n");return 0;}
你可以使用任何编辑工具来编写代码,nano 、 vi ,甚至记事本均可。
代码编辑完毕后,运行 gcc 命令进行编译:
$ lshello_world.c$ gcc -o hello_world hello_world.c
其中, -o 选项指定可执行程序名, hello_world.c 是源码文件。不出意外,当前目录下将出现一个可执行文件:
$ lshello_world hello_world.c
最后,还是在命令行下,将程序运行起来。看,程序输出预期内容:
$ ./hello_worldHello, world!
C++ 语言
C++ 语言编译与 C 语言类似,只不过编译工具不再是 gcc ,而是 g++ 。同样地, g++ 也可以通过包管理工具来安装:
$ sudo apt install g++
还是编译一个简单的程序 hello_world.cpp ,代码如下:
#include <iostream>using std::cout;using std::endl;int main() {cout << "Hello, world!" << endl;return 0;}
运行 g++ 命令进行编译,用法与 gcc 一样:
$ lshello_world.c$ g++ -o hello_world hello_world.cpp
编译完毕后,执行程序:
$ ./hello_worldHello, world!
多文件
大型程序一般由多个文件组成,编译多文件程序,将所有源码文件传给编译器即可。
以 C 语言为例,将 hello_world.c拆解成两个文件进行演示。首先是 say.c :
#include <stdio.h>void say_hello() {printf("Hello, world!\n");}
say.c 定义了一个函数,名为 say_hello 用于输出 Hello, world! 。
在 hello_world.c 中,直接调用 say_hello 即可:
void say_hello();int main() {say_hello();return 0;}
编译这个由两个文件组成的程序,步骤也非常简单:
$ gcc -o hello_world hello_world.c say.c
请注意,需要在 hello_world.c 中申明函数 say_hello 的原型(第 1 行),否则编译将输出以下警告:
hello_world.c:17:5: warning: implicit declaration of function 'say_hello' is invalid in C99 [-Wimplicit-function-declaration]say_hello();^1 warning generated.
原型申明相当于告诉编译器,say_hello 函数在别处定义,调用时不需要参数,也没有返回值。编译器编译 hello_world.c 时需要这个信息,因为 say_hello 函数的定义不在该文件下。
编译流程
如下图,程序编译可以进一步分成 编译 ( Compile )和 链接 ( Link )两个阶段:
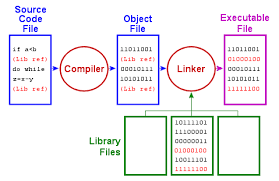
接下来,我们分阶段编译 multi-file2 ,源文件如下:
$ cd multi-file2$ lshello_world.c say.c say.h
先 编译say.c 文件,生成 say.o 对象文件:
$ gcc -c say.c$ lshello_world.c say.c say.h say.o
再 编译hello_world.c 文件,生成 hello_world.o 对象文件:
$ gcc -c hello_world.c$ lshello_world.c hello_world.o say.c say.h say.o
最后 链接 俩对象文件,生成可执行程序:
$ gcc -o hello_world hello_world.o say.o$ $ ./hello_worldHello, world!
注解
为啥要分阶段编译?
分阶段编译最大的好处是,可以进行部分编译—— 只编译有变更部分 。
假设例子中, hello_world.c 有变更,而 say.c 没有变更。那么,我们只需要编译 hello_world.c 生成新的 hello_world.o 对象文件,最后再跟先前的 say.o 文件链接生成新的可执行文件即可。
换句话将,我们省去了编译 say.c 的麻烦!这个小程序可能不明显,在大型程序中节省的编译时间非常可观。
自动构建
我们尝到部分编译的好处,但是区分哪些源码文件有变更是个麻烦事儿。而且,手工敲这么多编译命令也很无聊,我们急需一种能够自动构建的方法。
这时,我们可以借助自动化构建工具 make) :
$ sudo apt install make
构建规则定义在 Makefile 里:
.DEFAULT_GOAL := runsay.o: say.cgcc -o say.o -c say.chello_world.o: hello_world.cgcc -o hello_world.o -c hello_world.chello_world: say.o hello_world.ogcc -o hello_world say.o hello_world.orun: hello_world./hello_worldclean:rm -f *.orm -f hello_world
Makefile 规则可以很复杂,这里只介绍最基本的。
Makefile 大致可以理解成 目标 、 依赖 以及 构建指令 。
以第 3-4 行为例, say.o 是构建 目标 , say.c 是 依赖 ,其后以制表符( \t )缩进的行是 构建指令 。换句话将,要构建 say.o 需要依赖 say.c 源码文件,构建方法是执行 gcc 编译命令。
依赖定义清楚之后, make 可以决定什么情况下需要重新构建,什么情况下则不用。如果 say.c 有变更( mtime 比 say.o 大),则需要重新运行构建指令生成新的 say.o 。反之则不用。
此外,目标可以被其他目标所依赖,就像搭积木一样!执行程序( run ),依赖二进制程序( hello_world ),二进制程序则依赖两个目标文件( say.o, hello_world.o ),而目标文件又分别依赖各自的源码文件。通过递归, make 自动找到了构建并运行程序的方法!
Makefile 定义好后,运行 make 命令加上目标名即可构建指定的目标。例如,编译 say.o :
$ make say.o
或者编译并生产可执行程序( hello_world ):
$ make hello_world
make 命令将确保俩子目标( say.o 以及 hello_world.o )先被正确构建。
最后,一起感受一下自动构建有多爽。进入 auto-build 目录:
$ cd auto-build$ lshello_world.c Makefile say.c say.h
执行 make 命令:
$ makegcc -o say.o -c say.cgcc -o hello_world.o -c hello_world.cgcc -o hello_world say.o hello_world.o./hello_worldHello, world!
一个 make 命令搞定从编译到执行的所有环节!
注解
缺省情况下, Makefile 定义的第一个目标是默认目标。
我们在 Makefile 第一行显式定义了默认目标。
由于没有变更,再次构建时自动省略编译环节:
$ make./hello_worldHello, world!
顺便提一下,我们的 Makefile 还定义了一个用于清理编译结果的目标—— clean :
$ lsMakefile hello_world hello_world.c hello_world.o say.c say.h say.o$ make cleanrm -f *.orm -f hello_world$ lsMakefile hello_world.c say.c say.h
清理编译结果在打包源码、进行全新编译等场景特别有用。
程序库
可复用的代码,一般编译成程序库来使用。程序库可以分成两种:
- 静态链接库
- 动态链接库
静态库
静态库的全称是静态链接程序库,在程序编译阶段被链接进可执行程序。
接下来,我们将 say.c 编译成一个静态库,以此演示制作并使用静态库的方法。
进入 static-library 目录:
$ cd static-library$ lshello_world.c say.c say.h
编译 say.c :
$ gcc -c say.c$ lshello_world.c say.c say.h say.o
将目标文件打包成静态库,库名为 libsay.a :
$ ar -crv libsay.a say.oa - say.o$ lshello_world.c libsay.a say.c say.h say.o
编译 hello_world.c 时指定链接静态库:
$ gcc -o hello_world hello_world.c libsay.a$ ./hello_worldHello, world!
动态库
对应地,动态库的全称是动态链接程序库。
与静态库不同,动态库不链接进可执行程序。相反,程序只记录需要的动态库,直到运行时才搜索并加载。因此,采用动态库的程序,编译后生成的可执行文件更为短小。
接下来,我们将 say.c 编译成一个动态库,以此演示制作并使用动态库的方法。
进入 dynamic-library 目录:
$ cd dynamic-library$ lshello_world.c say.c say.h
编译 say.c :
$ gcc -fPIC -c say.c$ lshello_world.c say.c say.h say.o
注意到,通过 -fPIC 告诉 gcc 生成位置无关代码( Position-Independent Code )。这是制作动态库所必须的。
使用 gcc 生成动态库( -shared ),库名为 libsay.so :
$ gcc -shared -o libsay.so say.o$ lshello_world.c libsay.so say.c say.h say.o
在编译 hello_world.c 时,链接到生成的动态库:
$ gcc -o hello_world hello_world.c -L. -lsay
其中,选项 -L 指定动态库搜索路径; -l 指定需要链接的动态库名,可以多次指定。
好了,启动程序。然而,程序异常退出了:
$ ./hello_world./hello_world: error while loading shared libraries: libsay.so: cannot open shared object file: No such file or directory
原因是程序启动后找不到 libsay.so 动态库文件。
系统默认在 /lib 、 /usr/lib 等路径下搜索动态库。因此,可以将生成的动态库放置到上述目录再运行程序。
另一种方法是,通过 LD_LIBRARY_PATH 环境变量指定动态库搜索路径:
$ LD_LIBRARY_PATH=. ./hello_worldHello, world!
下一步
订阅更新,获取更多学习资料,请关注我们的 微信公众号 :
 小菜学编程
小菜学编程



