
光谱行动
译者:ApacheCN
torch.fft(input, signal_ndim, normalized=False) → Tensor
复杂到复杂的离散傅立叶变换
该方法计算复数到复数的离散傅立叶变换。忽略批量维度,它计算以下表达式:

其中  =
= signal_ndim是信号的维数, 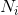 是信号维数
是信号维数  的大小。
的大小。
该方法支持1D,2D和3D复杂到复合变换,由signal_ndim表示。 input必须是最后一个尺寸为2的张量,表示复数的实部和虚部,并且至少应具有signal_ndim + 1尺寸和任意数量的前导批量尺寸。如果normalized设置为True,则通过将其除以  来将结果标准化,以便操作符是单一的。
来将结果标准化,以便操作符是单一的。
将实部和虚部一起作为input的相同形状的一个张量返回。
该函数的反函数是 ifft() 。
注意
对于CUDA张量,LRU高速缓存用于cuFFT计划,以加速在具有相同配置的相同几何的张量上重复运行FFT方法。
更改torch.backends.cuda.cufft_plan_cache.max_size(CUDA 10及更高版本上的默认值为4096,旧版本的CUDA上为1023)控制此缓存的容量。一些cuFFT计划可能会分配GPU内存。您可以使用torch.backends.cuda.cufft_plan_cache.size查询当前缓存中的计划数量,使用torch.backends.cuda.cufft_plan_cache.clear()清除缓存。
警告
对于CPU张量,此方法目前仅适用于MKL。使用torch.backends.mkl.is_available()检查是否安装了MKL。
参数:
- 输入 (Tensor) - 至少
signal_ndim+ 1维度的输入张量 - signal_ndim (int) - 每个信号中的维数。
signal_ndim只能是1,2或3 - 归一化 (bool, 任选) - 控制是否返回归一化结果。默认值:
False
| 返回: | 包含复数到复数傅立叶变换结果的张量 |
|---|---|
| 返回类型: | Tensor |
例:
>>> # unbatched 2D FFT>>> x = torch.randn(4, 3, 2)>>> torch.fft(x, 2)tensor([[[-0.0876, 1.7835],[-2.0399, -2.9754],[ 4.4773, -5.0119]],[[-1.5716, 2.7631],[-3.8846, 5.2652],[ 0.2046, -0.7088]],[[ 1.9938, -0.5901],[ 6.5637, 6.4556],[ 2.9865, 4.9318]],[[ 7.0193, 1.1742],[-1.3717, -2.1084],[ 2.0289, 2.9357]]])>>> # batched 1D FFT>>> torch.fft(x, 1)tensor([[[ 1.8385, 1.2827],[-0.1831, 1.6593],[ 2.4243, 0.5367]],[[-0.9176, -1.5543],[-3.9943, -2.9860],[ 1.2838, -2.9420]],[[-0.8854, -0.6860],[ 2.4450, 0.0808],[ 1.3076, -0.5768]],[[-0.1231, 2.7411],[-0.3075, -1.7295],[-0.5384, -2.0299]]])>>> # arbitrary number of batch dimensions, 2D FFT>>> x = torch.randn(3, 3, 5, 5, 2)>>> y = torch.fft(x, 2)>>> y.shapetorch.Size([3, 3, 5, 5, 2])
torch.ifft(input, signal_ndim, normalized=False) → Tensor
复数到复数的逆离散傅立叶变换
该方法计算复数到复数的离散傅里叶逆变换。忽略批量维度,它计算以下表达式:
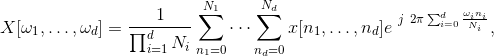
where = signal_ndim is number of dimensions for the signal, and is the size of signal dimension 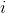 .
.
参数规范与 fft() 几乎相同。但是,如果normalized设置为True,则返回结果乘以  ,成为单一运算符。因此,要反转
,成为单一运算符。因此,要反转 fft() ,normalized参数应设置为 fft() 相同。
Returns the real and the imaginary parts together as one tensor of the same shape of input.
该函数的反函数是 fft() 。
Note
For CUDA tensors, an LRU cache is used for cuFFT plans to speed up repeatedly running FFT methods on tensors of same geometry with same same configuration.
Changing torch.backends.cuda.cufft_plan_cache.max_size (default is 4096 on CUDA 10 and newer, and 1023 on older CUDA versions) controls the capacity of this cache. Some cuFFT plans may allocate GPU memory. You can use torch.backends.cuda.cufft_plan_cache.size to query the number of plans currently in cache, and torch.backends.cuda.cufft_plan_cache.clear() to clear the cache.
Warning
For CPU tensors, this method is currently only available with MKL. Use torch.backends.mkl.is_available() to check if MKL is installed.
Parameters:
- 输入 (Tensor) - 至少
signal_ndim+ 1维度的输入张量 - signal_ndim (int) - 每个信号中的维数。
signal_ndim只能是1,2或3 - 归一化 (bool, 任选) - 控制是否返回归一化结果。默认值:
False
| Returns: | 包含复数到复数逆傅立叶变换结果的张量 |
|---|---|
| Return type: | Tensor |
Example:
>>> x = torch.randn(3, 3, 2)>>> xtensor([[[ 1.2766, 1.3680],[-0.8337, 2.0251],[ 0.9465, -1.4390]],[[-0.1890, 1.6010],[ 1.1034, -1.9230],[-0.9482, 1.0775]],[[-0.7708, -0.8176],[-0.1843, -0.2287],[-1.9034, -0.2196]]])>>> y = torch.fft(x, 2)>>> torch.ifft(y, 2) # recover xtensor([[[ 1.2766, 1.3680],[-0.8337, 2.0251],[ 0.9465, -1.4390]],[[-0.1890, 1.6010],[ 1.1034, -1.9230],[-0.9482, 1.0775]],[[-0.7708, -0.8176],[-0.1843, -0.2287],[-1.9034, -0.2196]]])
torch.rfft(input, signal_ndim, normalized=False, onesided=True) → Tensor
实对复离散傅立叶变换
该方法计算实数到复数的离散傅立叶变换。它在数学上等同于 fft() ,仅在输入和输出的格式上有所不同。
该方法支持1D,2D和3D实对复变换,由signal_ndim表示。 input必须是具有至少signal_ndim尺寸的张量,可选择任意数量的前导批量。如果normalized设置为True,则通过将其除以 来将结果标准化,以便操作符是单一的,其中 是信号的大小维 。
实对复傅里叶变换结果遵循共轭对称:

计算指数算术的模数是相应维数的大小,  是共轭算子, =
是共轭算子, = signal_ndim。 onesided标志控制是否避免输出结果中的冗余。如果设置为True(默认),输出将不是形状  的完整复杂结果,其中
的完整复杂结果,其中  是
是input的形状,而是最后一个尺寸将是大小  的一半。
的一半。
该函数的反函数是 irfft() 。
Note
For CUDA tensors, an LRU cache is used for cuFFT plans to speed up repeatedly running FFT methods on tensors of same geometry with same same configuration.
Changing torch.backends.cuda.cufft_plan_cache.max_size (default is 4096 on CUDA 10 and newer, and 1023 on older CUDA versions) controls the capacity of this cache. Some cuFFT plans may allocate GPU memory. You can use torch.backends.cuda.cufft_plan_cache.size to query the number of plans currently in cache, and torch.backends.cuda.cufft_plan_cache.clear() to clear the cache.
Warning
For CPU tensors, this method is currently only available with MKL. Use torch.backends.mkl.is_available() to check if MKL is installed.
Parameters:
- 输入 (Tensor) - 至少
signal_ndim维度的输入张量 - signal_ndim (int) - 每个信号中的维数。
signal_ndim只能是1,2或3 - 归一化 (bool, 任选) - 控制是否返回归一化结果。默认值:
False - 单独 (bool, 可选) - 控制是否返回一半结果以避免冗余。默认值:
True
| Returns: | 包含实数到复数傅立叶变换结果的张量 |
|---|---|
| Return type: | Tensor |
Example:
>>> x = torch.randn(5, 5)>>> torch.rfft(x, 2).shapetorch.Size([5, 3, 2])>>> torch.rfft(x, 2, onesided=False).shapetorch.Size([5, 5, 2])
torch.irfft(input, signal_ndim, normalized=False, onesided=True, signal_sizes=None) → Tensor
复数到实数的逆离散傅立叶变换
该方法计算复数到实数的逆离散傅里叶变换。它在数学上等同于 ifft() ,仅在输入和输出的格式上有所不同。
参数规范与 ifft() 几乎相同。类似于 ifft() ,如果normalized设置为True,则通过将其与 相乘来使结果归一化,以便运算符是单一的,其中 [] ](/static/images/loading.gif) 是信号维 的大小。
是信号维 的大小。
由于共轭对称性,input不需要包含完整的复频率值。大约一半的值就足够了, rfft() rfft(signal, onesided=True)给出input的情况就足够了。在这种情况下,将此方法的onesided参数设置为True。此外,原始信号形状信息有时会丢失,可选地将signal_sizes设置为原始信号的大小(如果处于批处理模式,则没有批量维度)以正确的形状恢复它。
因此,要反转 rfft() ,normalized和onesided参数应设置为 irfft() 相同,并且最好给出signal_sizes以避免大小不匹配。有关尺寸不匹配的情况,请参阅下面的示例。
有关共轭对称性的详细信息,请参见 rfft() 。
该函数的反函数是 rfft() 。
Warning
一般而言,此函数的输入应包含共轭对称后的值。请注意,即使onesided为True,仍然需要对某些部分进行对称。当不满足此要求时, irfft() 的行为未定义。由于 torch.autograd.gradcheck() 估计具有点扰动的数值雅可比行列式, irfft() 几乎肯定会失败。
Note
For CUDA tensors, an LRU cache is used for cuFFT plans to speed up repeatedly running FFT methods on tensors of same geometry with same same configuration.
Changing torch.backends.cuda.cufft_plan_cache.max_size (default is 4096 on CUDA 10 and newer, and 1023 on older CUDA versions) controls the capacity of this cache. Some cuFFT plans may allocate GPU memory. You can use torch.backends.cuda.cufft_plan_cache.size to query the number of plans currently in cache, and torch.backends.cuda.cufft_plan_cache.clear() to clear the cache.
Warning
For CPU tensors, this method is currently only available with MKL. Use torch.backends.mkl.is_available() to check if MKL is installed.
Parameters:
- 输入 (Tensor) - 至少
signal_ndim+ 1维度的输入张量 - signal_ndim (int) - 每个信号中的维数。
signal_ndim只能是1,2或3 - 归一化 (bool, 任选) - 控制是否返回归一化结果。默认值:
False - 单独 (bool, 任选) - 控制
input是否为半数以避免冗余,例如,rfft()。默认值:True - signal_sizes (列表或
torch.Size,可选) - 原始信号的大小(无批量维度)。默认值:None
| Returns: | 包含复数到实数逆傅立叶变换结果的张量 |
|---|---|
| Return type: | Tensor |
Example:
>>> x = torch.randn(4, 4)>>> torch.rfft(x, 2, onesided=True).shapetorch.Size([4, 3, 2])>>>>>> # notice that with onesided=True, output size does not determine the original signal size>>> x = torch.randn(4, 5)>>> torch.rfft(x, 2, onesided=True).shapetorch.Size([4, 3, 2])>>>>>> # now we use the original shape to recover x>>> xtensor([[-0.8992, 0.6117, -1.6091, -0.4155, -0.8346],[-2.1596, -0.0853, 0.7232, 0.1941, -0.0789],[-2.0329, 1.1031, 0.6869, -0.5042, 0.9895],[-0.1884, 0.2858, -1.5831, 0.9917, -0.8356]])>>> y = torch.rfft(x, 2, onesided=True)>>> torch.irfft(y, 2, onesided=True, signal_sizes=x.shape) # recover xtensor([[-0.8992, 0.6117, -1.6091, -0.4155, -0.8346],[-2.1596, -0.0853, 0.7232, 0.1941, -0.0789],[-2.0329, 1.1031, 0.6869, -0.5042, 0.9895],[-0.1884, 0.2858, -1.5831, 0.9917, -0.8356]])
torch.stft(input, n_fft, hop_length=None, win_length=None, window=None, center=True, pad_mode='reflect', normalized=False, onesided=True)
短时傅立叶变换(STFT)。
忽略可选批处理维度,此方法计算以下表达式:

其中  是滑动窗口的索引,
是滑动窗口的索引,  是
是  的频率。当
的频率。当onesided是默认值True时,
input必须是1-D时间序列或2-D批时间序列。- 如果
hop_length为None(默认值),则视为等于floor(n_fft / 4)。 - 如果
win_length为None(默认值),则视为等于n_fft。 window可以是尺寸win_length的1-D张量,例如来自torch.hann_window()。如果window是None(默认值),则视为在窗口中的任何地方都有 。如果 ,window将在施加之前在长度n_fft的两侧填充。- 如果
center为True(默认值),则input将在两侧填充,以便 帧在 时间居中。否则, - 帧在时间 开始。 pad_mode确定center为True时input上使用的填充方法。有关所有可用选项,请参阅torch.nn.functional.pad()。默认为"reflect"。- 如果
onesided是True(默认值),则仅返回 中 的值,因为实数到复数的傅里叶变换满足共轭对称性,即, 。 - 如果
normalized是True(默认为False),则该函数返回标准化的STFT结果,即乘以 。







将实部和虚部一起作为一个尺寸  返回,其中 是
返回,其中 是input,  的可选批量大小是应用STFT的频率的数量,
的可选批量大小是应用STFT的频率的数量,  是使用的帧的总数,并且最后维度中的每对表示作为实部和虚部的复数。
是使用的帧的总数,并且最后维度中的每对表示作为实部和虚部的复数。
Warning
此功能在0.4.1版本上更改了签名。使用先前的签名调用可能会导致错误或返回错误的结果。
Parameters:
- 输入 (Tensor) - 输入张量
- n_fft (int) - 傅立叶变换的大小
- hop_length (int, 可选) - 相邻滑动窗口帧之间的距离。默认值:
None(视为等于floor(n_fft / 4)) - win_length (int, 任选) - 窗口框架和STFT过滤器的大小。默认值:
None(视为等于n_fft) - 窗口 (Tensor, 可选) - 可选窗函数。默认值:
None(被视为所有 s的窗口) - 中心 (bool, 任选) - 是否在两侧垫
input使 第一帧以时间 为中心。默认值:True - pad_mode (string , 可选) - 控制
center为True时使用的填充方法。默认值:"reflect" - 归一化 (bool, 任选) - 控制是否返回归一化STFT结果默认值:
False - 单独 (bool, 可选) - 控制是否返回一半结果以避免冗余默认:
True
| Returns: | 包含具有上述形状的STFT结果的张量 |
|---|---|
| Return type: | Tensor |
torch.bartlett_window(window_length, periodic=True, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
巴特利特的窗口功能。

其中 是完整的窗口大小。
输入window_length是控制返回窗口大小的正整数。 periodic标志确定返回的窗口是否从对称窗口中删除最后一个重复值,并准备用作具有 torch.stft() 等功能的周期窗口。因此,如果periodic为真,则上式中的 实际上是  。此外,我们总是
。此外,我们总是torch.bartlett_window(L, periodic=True)等于torch.bartlett_window(L + 1, periodic=False)[:-1])。
Note
如果window_length  ,则返回的窗口包含单个值1。
,则返回的窗口包含单个值1。
Parameters:
- window_length (int) - 返回窗口的大小
- 周期性 (bool, 可选) - 如果为True,则返回一个窗口作为周期函数。如果为False,则返回对称窗口。
- dtype (
torch.dtype,可选) - 返回张量的所需数据类型。默认值:ifNone,使用全局默认值(参见torch.set_default_tensor_type())。仅支持浮点类型。 - 布局 (
torch.layout,可选) - 返回窗口张量的理想布局。仅支持torch.strided(密集布局)。 - 设备 (
torch.device,可选) - 返回张量的所需设备。默认值:如果None,则使用当前设备作为默认张量类型(参见torch.set_default_tensor_type())。device将是CPU张量类型的CPU和CUDA张量类型的当前CUDA设备。 - requires_grad (bool, 可选) - 如果autograd应该记录对返回张量的操作。默认值:
False。
| Returns: | 含有窗口的1-D张量  |
|---|---|
| Return type: | Tensor |
torch.blackman_window(window_length, periodic=True, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
布莱克曼窗口功能。

where is the full window size.
输入window_length是控制返回窗口大小的正整数。 periodic标志确定返回的窗口是否从对称窗口中删除最后一个重复值,并准备用作具有 torch.stft() 等功能的周期窗口。因此,如果periodic为真,则上式中的 实际上是 。此外,我们总是torch.blackman_window(L, periodic=True)等于torch.blackman_window(L + 1, periodic=False)[:-1])。
Note
If window_length , the returned window contains a single value 1.
Parameters:
- window_length (int) - 返回窗口的大小
- 周期性 (bool, 可选) - 如果为True,则返回一个窗口作为周期函数。如果为False,则返回对称窗口。
- dtype (
torch.dtype,可选) - 返回张量的所需数据类型。默认值:ifNone,使用全局默认值(参见torch.set_default_tensor_type())。仅支持浮点类型。 - 布局 (
torch.layout,可选) - 返回窗口张量的理想布局。仅支持torch.strided(密集布局)。 - 设备 (
torch.device,可选) - 返回张量的所需设备。默认值:如果None,则使用当前设备作为默认张量类型(参见torch.set_default_tensor_type())。device将是CPU张量类型的CPU和CUDA张量类型的当前CUDA设备。 - requires_grad (bool, 可选) - 如果autograd应该记录对返回张量的操作。默认值:
False。
| Returns: | A 1-D tensor of size containing the window |
|---|---|
| Return type: | Tensor |
torch.hamming_window(window_length, periodic=True, alpha=0.54, beta=0.46, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
汉明窗功能。

where is the full window size.
输入window_length是控制返回窗口大小的正整数。 periodic标志确定返回的窗口是否从对称窗口中删除最后一个重复值,并准备用作具有 torch.stft() 等功能的周期窗口。因此,如果periodic为真,则上式中的 实际上是 。此外,我们总是torch.hamming_window(L, periodic=True)等于torch.hamming_window(L + 1, periodic=False)[:-1])。
Note
If window_length , the returned window contains a single value 1.
Note
这是 torch.hann_window() 的通用版本。
Parameters:
- window_length (int) - 返回窗口的大小
- 周期性 (bool, 可选) - 如果为True,则返回一个窗口作为周期函数。如果为False,则返回对称窗口。
- dtype (
torch.dtype,可选) - 返回张量的所需数据类型。默认值:ifNone,使用全局默认值(参见torch.set_default_tensor_type())。仅支持浮点类型。 - 布局 (
torch.layout,可选) - 返回窗口张量的理想布局。仅支持torch.strided(密集布局)。 - 设备 (
torch.device,可选) - 返回张量的所需设备。默认值:如果None,则使用当前设备作为默认张量类型(参见torch.set_default_tensor_type())。device将是CPU张量类型的CPU和CUDA张量类型的当前CUDA设备。 - requires_grad (bool, 可选) - 如果autograd应该记录对返回张量的操作。默认值:
False。
| Returns: | A 1-D tensor of size containing the window |
|---|---|
| Return type: | Tensor |
torch.hann_window(window_length, periodic=True, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
汉恩窗功能。

where is the full window size.
输入window_length是控制返回窗口大小的正整数。 periodic标志确定返回的窗口是否从对称窗口中删除最后一个重复值,并准备用作具有 torch.stft() 等功能的周期窗口。因此,如果periodic为真,则上式中的 实际上是 。此外,我们总是torch.hann_window(L, periodic=True)等于torch.hann_window(L + 1, periodic=False)[:-1])。
Note
If window_length , the returned window contains a single value 1.
Parameters:
- window_length (int) - 返回窗口的大小
- 周期性 (bool, 可选) - 如果为True,则返回一个窗口作为周期函数。如果为False,则返回对称窗口。
- dtype (
torch.dtype,可选) - 返回张量的所需数据类型。默认值:ifNone,使用全局默认值(参见torch.set_default_tensor_type())。仅支持浮点类型。 - 布局 (
torch.layout,可选) - 返回窗口张量的理想布局。仅支持torch.strided(密集布局)。 - 设备 (
torch.device,可选) - 返回张量的所需设备。默认值:如果None,则使用当前设备作为默认张量类型(参见torch.set_default_tensor_type())。device将是CPU张量类型的CPU和CUDA张量类型的当前CUDA设备。 - requires_grad (bool, 可选) - 如果autograd应该记录对返回张量的操作。默认值:
False。
| Returns: | A 1-D tensor of size containing the window |
|---|---|
| Return type: | Tensor |


