
Using your browser’s Developer Tools for scraping
Here is a general guide on how to use your browser’s Developer Toolsto ease the scraping process. Today almost all browsers come withbuilt in Developer Tools and although we will use Firefox in thisguide, the concepts are applicable to any other browser.
In this guide we’ll introduce the basic tools to use from a browser’sDeveloper Tools by scraping quotes.toscrape.com.
Caveats with inspecting the live browser DOM
Since Developer Tools operate on a live browser DOM, what you’ll actually seewhen inspecting the page source is not the original HTML, but a modified oneafter applying some browser clean up and executing Javascript code. Firefox,in particular, is known for adding <tbody> elements to tables. Scrapy, onthe other hand, does not modify the original page HTML, so you won’t be able toextract any data if you use <tbody> in your XPath expressions.
Therefore, you should keep in mind the following things:
- Disable Javascript while inspecting the DOM looking for XPaths to beused in Scrapy (in the Developer Tools settings click Disable JavaScript)
- Never use full XPath paths, use relative and clever ones based on attributes(such as
id,class,width, etc) or any identifying features likecontains(@href, 'image'). - Never include
<tbody>elements in your XPath expressions unless youreally know what you’re doing
Inspecting a website
By far the most handy feature of the Developer Tools is the _Inspector_feature, which allows you to inspect the underlying HTML code ofany webpage. To demonstrate the Inspector, let’s look at thequotes.toscrape.com-site.
On the site we have a total of ten quotes from various authors with specifictags, as well as the Top Ten Tags. Let’s say we want to extract all the quoteson this page, without any meta-information about authors, tags, etc.
Instead of viewing the whole source code for the page, we can simply right clickon a quote and select Inspect Element (Q), which opens up the Inspector.In it you should see something like this: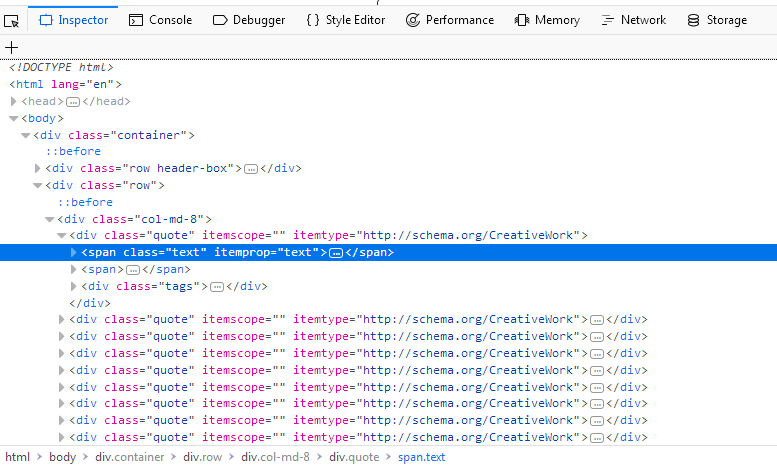 The interesting part for us is this:
The interesting part for us is this:
- <div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
- <span class="text" itemprop="text">(...)</span>
- <span>(...)</span>
- <div class="tags">(...)</div>
- </div>
If you hover over the first div directly above the span tag highlightedin the screenshot, you’ll see that the corresponding section of the webpage getshighlighted as well. So now we have a section, but we can’t find our quote textanywhere.
The advantage of the Inspector is that it automatically expands and collapsessections and tags of a webpage, which greatly improves readability. You canexpand and collapse a tag by clicking on the arrow in front of it or by doubleclicking directly on the tag. If we expand the span tag with the class="text" we will see the quote-text we clicked on. The Inspector lets youcopy XPaths to selected elements. Let’s try it out.
First open the Scrapy shell at http://quotes.toscrape.com/ in a terminal:
- $ scrapy shell "http://quotes.toscrape.com/"
Then, back to your web browser, right-click on the span tag, selectCopy > XPath and paste it in the Scrapy shell like so:
- >>> response.xpath('/html/body/div/div[2]/div[1]/div[1]/span[1]/text()').getall()
- ['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
Adding text() at the end we are able to extract the first quote with thisbasic selector. But this XPath is not really that clever. All it does isgo down a desired path in the source code starting from html. So let’ssee if we can refine our XPath a bit:
If we check the Inspector again we’ll see that directly beneath ourexpanded div tag we have nine identical div tags, each with thesame attributes as our first. If we expand any of them, we’ll see the samestructure as with our first quote: Two span tags and one div tag. We canexpand each span tag with the class="text" inside our div tags andsee each quote:
- <div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
- <span class="text" itemprop="text">
- “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
- </span>
- <span>(...)</span>
- <div class="tags">(...)</div>
- </div>
With this knowledge we can refine our XPath: Instead of a path to follow,we’ll simply select all span tags with the class="text" by usingthe has-class-extension:
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
And with one simple, cleverer XPath we are able to extract all quotes fromthe page. We could have constructed a loop over our first XPath to increasethe number of the last div, but this would have been unnecessarilycomplex and by simply constructing an XPath with has-class("text")we were able to extract all quotes in one line.
The Inspector has a lot of other helpful features, such as searching in thesource code or directly scrolling to an element you selected. Let’s demonstratea use case:
Say you want to find the Next button on the page. Type Next into thesearch bar on the top right of the Inspector. You should get two results.The first is a li tag with the class="next", the second the textof an a tag. Right click on the a tag and select Scroll into View.If you hover over the tag, you’ll see the button highlighted. From herewe could easily create a Link Extractor tofollow the pagination. On a simple site such as this, there may not bethe need to find an element visually but the Scroll into View functioncan be quite useful on complex sites.
Note that the search bar can also be used to search for and test CSSselectors. For example, you could search for span.text to findall quote texts. Instead of a full text search, this searches forexactly the span tag with the class="text" in the page.
The Network-tool
While scraping you may come across dynamic webpages where some partsof the page are loaded dynamically through multiple requests. Whilethis can be quite tricky, the Network-tool in the Developer Toolsgreatly facilitates this task. To demonstrate the Network-tool, let’stake a look at the page quotes.toscrape.com/scroll.
The page is quite similar to the basic quotes.toscrape.com-page,but instead of the above-mentioned Next button, the pageautomatically loads new quotes when you scroll to the bottom. Wecould go ahead and try out different XPaths directly, but insteadwe’ll check another quite useful command from the Scrapy shell:
$ scrapy shell "quotes.toscrape.com/scroll" (...) >>> view(response)
A browser window should open with the webpage but with onecrucial difference: Instead of the quotes we just see a greenishbar with the word Loading…. The
The view(response) command let’s us view the response ourshell or later our spider receives from the server. Here we seethat some basic template is loaded which includes the title,the login-button and the footer, but the quotes are missing. Thistells us that the quotes are being loaded from a different requestthan quotes.toscrape/scroll.
If you click on the Network tab, you will probably only seetwo entries. The first thing we do is enable persistent logs byclicking on Persist Logs. If this option is disabled, thelog is automatically cleared each time you navigate to a differentpage. Enabling this option is a good default, since it gives uscontrol on when to clear the logs.
If we reload the page now, you’ll see the log get populated with sixnew requests.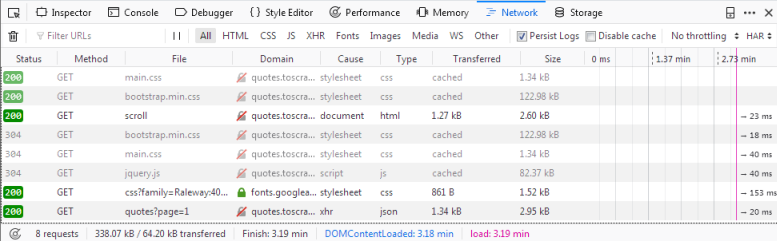 Here we see every request that has been made when reloading the pageand can inspect each request and its response. So let’s find outwhere our quotes are coming from:
Here we see every request that has been made when reloading the pageand can inspect each request and its response. So let’s find outwhere our quotes are coming from:
First click on the request with the name scroll. On the rightyou can now inspect the request. In Headers you’ll find detailsabout the request headers, such as the URL, the method, the IP-address,and so on. We’ll ignore the other tabs and click directly on Response.
What you should see in the Preview pane is the rendered HTML-code,that is exactly what we saw when we called view(response) in theshell. Accordingly the type of the request in the log is html.The other requests have types like css or js, but whatinterests us is the one request called quotes?page=1 with thetype json.
If we click on this request, we see that the request URL ishttp://quotes.toscrape.com/api/quotes?page=1 and the responseis a JSON-object that contains our quotes. We can also right-clickon the request and open Open in new tab to get a better overview.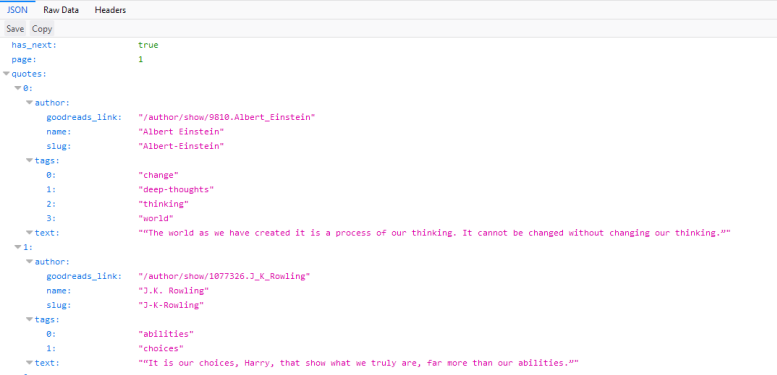 With this response we can now easily parse the JSON-object andalso request each page to get every quote on the site:
With this response we can now easily parse the JSON-object andalso request each page to get every quote on the site:
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api/quotes?page=1']
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = "http://quotes.toscrape.com/api/quotes?page={}".format(self.page)
yield scrapy.Request(url=url, callback=self.parse)
This spider starts at the first page of the quotes-API. With eachresponse, we parse the response.text and assign it to data.This lets us operate on the JSON-object like on a Python dictionary.We iterate through the quotes and print out the quote["text"].If the handy has_next element is true (try loadingquotes.toscrape.com/api/quotes?page=10 in your browser or apage-number greater than 10), we increment the page attributeand yield a new request, inserting the incremented page-numberinto our url.
In more complex websites, it could be difficult to easily reproduce therequests, as we could need to add headers or cookies to make it work.In those cases you can export the requests in cURLformat, by right-clicking on each of them in the network tool and using thefrom_curl() method to generate an equivalentrequest:
from scrapy import Request
request = Request.from_curl(
"curl 'http://quotes.toscrape.com/api/quotes?page=1' -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
Alternatively, if you want to know the arguments needed to recreate thatrequest you can use the scrapy.utils.curl.curl_to_request_kwargs()function to get a dictionary with the equivalent arguments.
As you can see, with a few inspections in the Network-tool wewere able to easily replicate the dynamic requests of the scrollingfunctionality of the page. Crawling dynamic pages can be quitedaunting and pages can be very complex, but it (mostly) boils downto identifying the correct request and replicating it in your spider.


