
This section covers the following topics:
- Volume Size
- Snapshots
- Backups
- Maintenance Mode
- Replica Count
- Volume Parameters
- Disaster Recovery Volumes
- Backupstore Update Intervals, RTO, and RPO
The Longhorn Volume Manager container runs on each host in the Longhorn cluster. as a Kubernetes DaemonSet. The Longhorn Volume Manager handles the API calls from the UI or the Flex Volume and CSI Kubernetes plugins.
When the Longhorn manager is asked to create a volume, it creates a controller container on the host the volume is attached to as well as the hosts where the replicas will be placed. Replicas should be placed on separate hosts to ensure maximum availability.
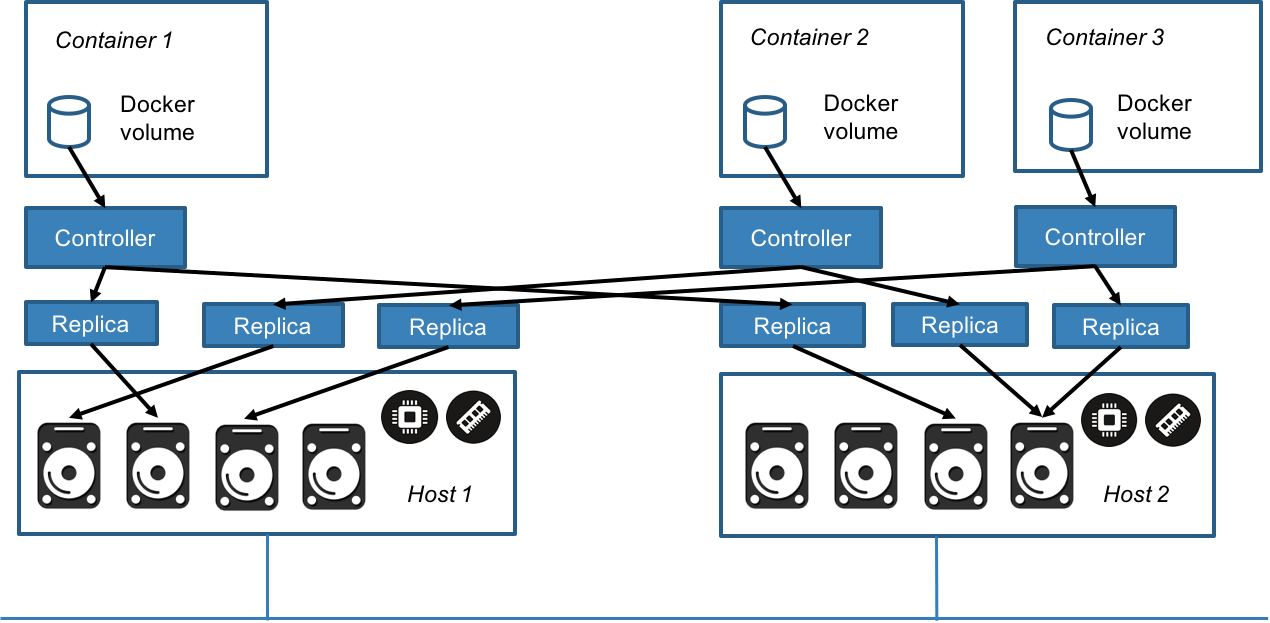
Volume Size
Longhorn is a thin-provisioned storage system. That means a Longhorn volume will only take the space it needs at the moment. For example, if you allocated a 20GB volume but only use 1GB of it, the actual data size on your disk would be 1GB. You can see the actual data size in the volume details in the UI.
Longhorn volume itself cannot shrink in size if you’ve removed content from your volume. For example, if you create a volume of 20GB, used 10GB, then removed the content of 9GB, the actual size on the disk would still be 10GB instead of 1GB. It’s because currently Longhorn operates on the block level, not filesystem level, so it doesn’t know if user has removed the content or not. That information is mostly kept in the filesystem level.
Snapshots
Space Taken by the Snapshots
Some users may found that a Longhorn volume’s actual size is bigger than its nominal size. That’s because in Longhorn, snapshot stored the history data of the volume, which will also take some spaces, depends on how much data was in the snapshot. The snapshot feature enables user to revert back to a certain point in history, create a backup to secondary storage. The snapshot feature is also a part Longhorn on rebuilding process. Every time when Longhorn detects a replica is down, it will take a (system) snapshot automatically and start rebuilding on another node.
To reduce the space taken by snapshots, user can schedule a recurring snapshot or backup with a retain number, which will automatically create a new snapshot/backup on schedule, then clean up for any excessive snapshots/backups.
User can also delete unwanted snapshot manually through UI. Any system generated snapshots will be automatically marked for deletion if the deletion of any snapshot was triggered.
The Latest Snapshot
In Longhorn, the latest snapshot cannot be deleted. It because whenever a snapshot is deleted, Longhorn will coalesce it content with the next snapshot, makes sure the next and later snapshot will still have the correct content. But Longhorn cannot do that for the last snapshot since there is no next snapshot to it. The next “snapshot” of the last snapshot is the live volume(volume-head), which is being read/written by the user at the moment, so the coalescing process cannot happen. Instead, the latest snapshot will be marked as removed, and it will be cleaned up next time when possible.
If the users want to clean up the latest snapshot, they can create a new snapshot, then remove the previous “latest” snapshot.
Note about Block Level Snapshots
Longhorn is a crash-consistent block storage solution.
It’s normal for the OS to keep content in the cache before writing into the block layer. However, it also means if the all the replicas are down, then Longhorn may not contain the immediate change before the shutdown, since the content was kept in the OS level cache and hadn’t transferred to Longhorn system yet. It’s similar to if your desktop was down due to a power outage, after resuming the power, you may find some weird files in the hard drive.
To force the data being written to the block layer at any given moment, the user can run sync command on the node manually, or unmount the disk. The OS would write the content from the cache to the block layer in either situation.
Longhorn will also run the sync command automatically before creating a snapshot.
Backups
A backup in Longhorn represents a volume state (a snapshot) at a given time, stored in the secondary storage (the Longhorn backupstore) which is outside of the Longhorn system. Backup creation will involving copying the data through the network, so it will take time.
Backup operations can be scheduled using the recurring snapshot and backup feature, but they can also be done as needed. It’s recommended to schedule recurring backups for your volumes. If a backupstore is not available, it’s recommended to have the recurring snapshot scheduled instead.
A corresponding snapshot is needed for creating a backup. And user can choose to back up any snapshot previously created.
Maintenance Mode
After v0.6.0, when the user attaching the volume from Longhorn UI, there is a checkbox for Maintenance mode. The option will result in attaching the volume without enabling the frontend (block device or iSCSI), to make sure no one can access the volume data when the volume is attached.
It’s mainly used to perform Snapshot Revert. After v0.6.0, Snapshot Reverting operation required volume to be in Maintenance mode since we cannot modify the block device’s content with the volume mounted or being used, otherwise it will cause filesystem corruptions.
It’s also useful to inspect the volume state without worry that the data can be accessed by accident.
Replica Count
The default replica count can be changed in the setting.
Also, when a volume is attached, the user can change the replica count for the volume in the UI.
Longhorn will always try to maintain at least given number of healthy replicas for each volume.
If the current healthy replica count is less than specified replica count, Longhorn will start rebuilding new replicas.
If the current healthy replica count is more than specified replica count, Longhorn will do nothing. In this situation, if user delete one or more healthy replicas, or there are healthy replicas failed, as long as the total healthy replica count doesn’t dip below the specified replica count, Longhorn won’t start rebuilding new replicas.
Volume parameters
Stale Replica Timeout
Stale Replica Timeout (staleReplicaTimeout) determines when would Longhorn cleanup an error replica after the replica become ERROR. Unit is in minutes. Default is 2880 (48 hours)
Disaster Recovery Volumes
A disaster recovery (DR) volume is a special volume that stores data in a backup cluster in case the whole main cluster goes down. DR volumes are used to increase the resiliency of Longhorn volumes.
Because the main purpose of a DR volume is to restore data from backup, this type of volume doesn’t support the following actions before it is activated:
- Creating, deleting, and reverting snapshots
- Creating backups
- Creating persistent volumes
- Creating persistent volume claims
A DR volume can be created from a volume’s backup in the backup store. After the DR volume is created, Longhorn will monitor its original backup volume and incrementally restore from the latest backup.
If the original volume in the main cluster goes down, the DR volume can be immediately activated in the backup cluster, so it can greatly reduce the time needed to restore the data from the backup store to the volume in the backup cluster.
When a DR volume is activated, Longhorn will check the last backup of the original volume. If the backup hasn’t been restored, the restoration will be started, and the activate action will fail. Users need to wait for the restoration to complete before retrying.
The Backup Target in Settings cannot be updated if any DR volumes exist.
Backupstore Update Intervals, RTO, and RPO
Typically incremental restoration is triggered by the periodic backup store update. Users can set backup store update interval in Setting - General - Backupstore Poll Interval.
Notice that this interval can potentially impact Recovery Time Objective (RTO). If it is too long, there may be a large amount of data for the disaster recovery volume to restore, which will take a long time.
As for Recovery Point Objective (RPO), it is determined by recurring backup scheduling of the backup volume. If recurring backup scheduling for normal volume A creates a backup every hour, then the RPO is one hour. You can check here to see how to set recurring backups in Longhorn.
The following analysis assumes that the volume creates a backup every hour, and that incrementally restoring data from one backup takes five minutes:
- If the
Backupstore Poll Intervalis 30 minutes, then there will be at most one backup worth of data since the last restoration. The time for restoring one backup is five minutes, so the RTO would be five minutes. - If
Backupstore Poll Intervalis 12 hours, then there will be at most 12 backups worth of data since last restoration. The time for restoring the backups is 5 * 12 = 60 minutes, so the RTO would be 60 minutes.


